
"이제 우리는 Mk1 IPU 시스템에서 이전에 수행했던 것보다 50~100배 더 많은 실험을 진행하고 있습니다."

Phil Brown
애플리케이션 이사
이 글에서는 Weights & Biases는 Graphcore가 고급 IPU 하드웨어에서 실행되는 실험 수를 기하급수적으로 늘리는 데 도움이 되었습니다.
.
그래프코어 소개
그래프코어는 현재 및 차세대 인공 지능 워크로드의 요구 사항에 맞게 설계된 세계에서 가장 정교한 마이크로프로세서인 지능 처리 장치(IPU)를 개발한 기업입니다.
.
.
Graphcore의 시스템은 AI 워크로드를 획기적으로 가속화할 뿐만 아니라 혁신가가 새롭고 더욱 정교한 모델을 개발할 수 있도록 지원합니다. 많은 AI 훈련 및 추론 작업에서 IPU 시스템은 완전히 새로운 종류의 실리콘 아키텍처를 기반으로 하기 때문에 최신 GPU 기반 시스템보다 훨씬 뛰어난 성능을 발휘합니다.
.
.
대규모 배포의 경우 Graphcore의 IPU-POD 플랫폼은 다수의 IPU 프로세서에서 매우 큰 모델을 병렬로 실행하거나 여러 사용자 및 작업에서 컴퓨팅 리소스를 공유하는 기능을 제공합니다.
.
.
Graphcore 하드웨어에서 BERT 확장
Most of our readers are likely familiar with BERT, 2018년 Google이 출시한 Transformers 모델의 양방향 인코더 표현. 기본적으로 BERT는 Generative Pre-trained와 같은 이전 단방향 모델보다 컨텍스트를 훨씬 더 잘 이해합니다.
Transformers (GPTs). 예를 들어, BERT는 영어에서 다양한 의미를 갖는 “run”과 같은 단어 간의 차이점을 알 가능성이 훨씬 더 높습니다. 특정 문장에서 “실행”이 무엇을 의미하는지 파악하기 위해 여러 방향(따라서 “양방향”)을 살펴보기 때문입니다. 결국, 최신 모델의 “달리기”는 런닝머신에서의 “달리기”와 많이 다릅니다
.
Transformers (GPTs). 예를 들어, BERT는 영어에서 다양한 의미를 갖는 “run”과 같은 단어 간의 차이점을 알 가능성이 훨씬 더 높습니다. 특정 문장에서 “실행”이 무엇을 의미하는지 파악하기 위해 여러 방향(따라서 “양방향”)을 살펴보기 때문입니다. 결국, 최신 모델의 “달리기”는 런닝머신에서의 “달리기”와 많이 다릅니다
.
BERT는 Google이 이제 거의 모든 영어 검색에 사용할 만큼 성공적이었습니다. 이는 다양한 상황에 적용되었으며 여러 SOTA 접근 방식의 구성 요소였습니다.
NLP 하지만 비디오, 컴퓨터 비전, 단백질 특징 추출과 같이 서로 다른 영역에서 사용됩니다.
NLP 하지만 비디오, 컴퓨터 비전, 단백질 특징 추출과 같이 서로 다른 영역에서 사용됩니다.
BERT도 상당히 큰 모델입니다. BERT 기반 변형에는 1억 1천만 개의 매개변수가 있는 반면 BERT-large에는 3억 4천만 개의 매개변수가 있습니다. 실제로 이러한 대형 모델 중 일부에는 1,000억 개가 넘는 매개변수가 있을 수 있습니다.
.
.
이제 BERT와 같은 모델의 보급이 증가함에 따라 그에 수반되는 컴퓨팅 탐욕을 따라잡을 수 있는 하드웨어에 대한 수요가 증가하고 있습니다. 그리고 이는 Graphcore가 그들의 솔루션을 통해 해결하는 데 도움이 되는 문제입니다.
Intelligence Processing Units (or IPUs).
Intelligence Processing Units (or IPUs).
IPU는 BERT와 같은 대규모 모델과 더 큰 차세대 모델을 처리하기 위해 만들어진 AI 프로세서입니다. 일반적으로 POD로 서로 연결됩니다. 즉, 이러한 모델 교육은 며칠 또는 몇 시간이라는 합리적인 기간 내에 완료될 수 있습니다.
.
.
Graphcore 자체가 작성했습니다.
eloquently about their processes here. 기본적으로 이들은 연결된 여러 IPU(즉, IPU-POD)를 사용하고 다양한 데이터 병렬 모델 교육 기술을 사용하여 사전 교육 프로세스를 이러한 여러 시스템으로 확장합니다. 우리는 그들이 설명하도록 할 것입니다
:
eloquently about their processes here. 기본적으로 이들은 연결된 여러 IPU(즉, IPU-POD)를 사용하고 다양한 데이터 병렬 모델 교육 기술을 사용하여 사전 교육 프로세스를 이러한 여러 시스템으로 확장합니다. 우리는 그들이 설명하도록 할 것입니다
:
“데이터 병렬 교육에는 교육 데이터 세트를 여러 부분으로 나누는 작업이 포함되며, 각 부분은 모델 복제본에서 사용됩니다. 각 최적화 단계에서 가중치 업데이트와 모델 상태가 모든 복제본에서 동일하도록 모든 복제본에서 기울기가 평균 감소됩니다.
“
“
Graphcore 엔지니어는 또한 Gradient Accumulation을 사용하여 대규모 배치로 BERT를 교육할 때 병렬 확장 효율성을 유지하는 데 도움을 줍니다.
.
.
최종 결과는 BERT 교육 시간이 엄청나게 빠르다는 것입니다. 자체 PopART 시스템에서는 12시간이 조금 넘습니다. 아래에서 해당 성능을 볼 수 있습니다.
.
.
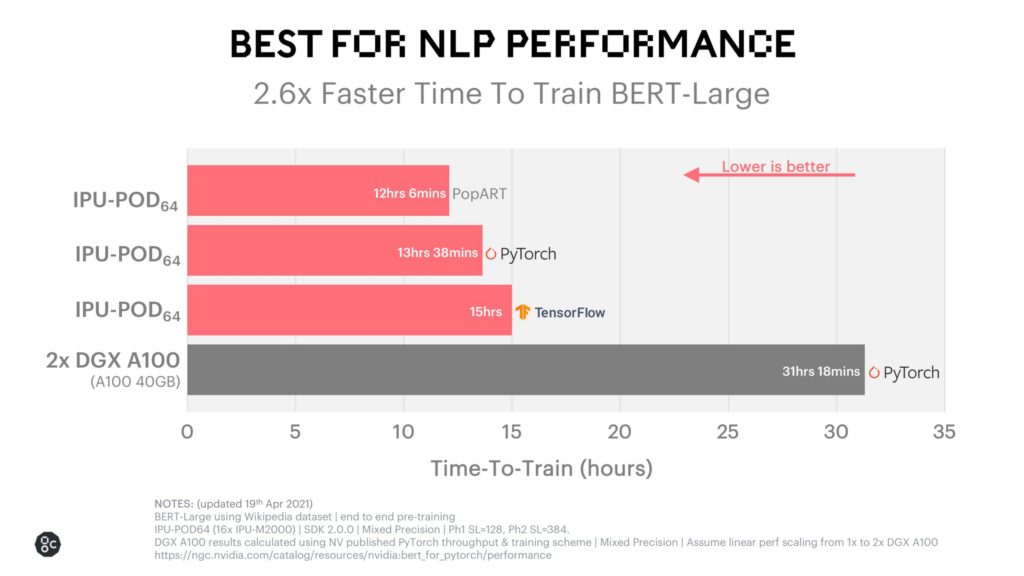
Graphcore의 고객 기반은 크고 복잡한 모델을 운영하는 스마트하고 혁신적인 회사로 가득 차 있습니다. 늘어나는 사용자 기반을 지원하려면 이 인프라를 구축하는 것이 핵심입니다. 그러나 이러한 모든 IPU를 결합하고 이렇게 대규모 실험을 실행하는 것은 가볍게 말하면 어려운 작업입니다. 그곳이 Weights & 편견이 들어온다
.
.
가중치 및 가중치를 사용한 IPU 실험 확장 편견
Graphcore의 IPU-POD를 통해 AI 엔지니어가 BERT와 같은 매개변수가 풍부한 모델을 더 빠르게 훈련할 수 있었던 것과 마찬가지로 W&B는 Graphcore 팀이 실험을 확장하는 데 도움을 주었습니다.
.
.
Weights & 편향 도구, Graphcore는 많은 팀이 하는 일을 수행했습니다. 즉, 내부 도구를 구축하고 스프레드시트에서 수동으로 실험을 추적했습니다.
.
.
이러한 접근 방식에는 몇 가지 까다로운 문제가 발생했습니다. 우선, 여러 IPU-POD 시스템과 여러 배포 위치에서 실험을 추적하는 데 문제가 있었습니다. 즉, 접근 방식을 확장하는 것이 너무 복잡해 효과적으로 추적할 수 없었고, 대상 머신 러닝 모델을 활성화하려면 대규모 실험이 중요했기 때문에 문제가 되었습니다. 또한 작업을 분석할 수 있는 중앙 장소나 팀 전체에서 공동 작업하고 결과를 공유할 수 있는 쉬운 방법도 없었습니다.
이러한 과제에 더해 여러 시스템에서 대규모 모델을 교육하는 것은 정말 복잡한 작업입니다. 몇 가지 잠재적인 어려움을 언급하자면 모델 자체, 데이터 세트 또는 소프트웨어의 버그로 인해 문제가 발생할 수 있습니다. 이러한 실패 지점을 진단하려면 모든 작업을 기록할 수 있고 시간을 되돌아보고 이전 실험과 현재 실험을 비교하는 데 사용할 수 있는 중앙 진실 소스가 필요했습니다.
.
.
내부 솔루션은 일부 문제를 처리할 수 있었지만 Graphcore의 작업이 복잡해질수록 내부 솔루션이 더 많이 필요했습니다. W&B는 “명백한 선택”이었습니다.
“이제 우리는 Mk1 IPU 시스템에서 이전에 수행했던 것보다 50~100배 더 많은 실험을 진행하고 있습니다.”라고 Graphcore의 애플리케이션 이사인 Phil Brown은 이렇게 설명했습니다.
W&B를 사용하면 구축 중인 시스템을 확장하면서 실험도 확장할 수 있습니다. 이를 통해 무엇이 잘못되었는지 더 빨리 발견하고 더 빨리 수정할 수 있습니다. 이는 계측한 날까지 거슬러 올라가는 중앙 정보 소스를 제공하므로 몇 달 전의 성공적인 실행을 비교하고 새로운 통찰력을 얻을 수 있습니다. 이를 통해 이러한 실험에서 가변적인 성능이 예상되는지 또는 디버깅이 필요한 문제가 있는지 이해할 수 있습니다. 그리고 그들은 시각화도 좋아합니다.
.
.
그래프코어의 다음 단계
Graphcore is continuing to build not only bigger and more powerful IPUs and IPU-PODs but also building out a software ecosystem as well. W&B를 계측한다는 것은 고객이 현재와 미래의 모델이 더 커짐에 따라 최첨단 모델을 교육하는 데 필요한 시스템과 소프트웨어를 제공하는 데 집중할 수 있음을 의미합니다.
.
.
실수하지 마십시오. 모델은 성장할 것입니다. 실제로 SOTA NLP 모델은 매년 10배 더 커지고 있는 것으로 추정됩니다. 분산 컴퓨팅은 반드시 필요합니다. 모델의 크기와 복잡성이 계속해서 확장되고 있으므로 IPU는 탁월한 선택입니다.
.
.