
„Wir führen jetzt 50- bis 100-mal mehr Experimente durch als zuvor auf den Mk1-IPU-Systemen.“

Phil Brown
Leiter der Anwendungsabteilung
In diesem Artikel werfen wir einen Blick darauf, wie Weights & Biases Graphcore dabei geholfen hat, die Anzahl der auf seiner fortschrittlichen IPU-Hardware ausgeführten Experimente exponentiell zu steigern.
Über Graphcore
Graphcore ist der Erfinder der Intelligence Processing Unit (IPU), dem weltweit fortschrittlichsten Mikroprozessor, der für die Anforderungen aktueller und zukünftiger Workloads im Bereich künstliche Intelligenz entwickelt wurde.
Die Systeme von Graphcore können KI-Workloads drastisch beschleunigen und Innovatoren die Entwicklung neuer, ausgefeilterer Modelle ermöglichen. Bei vielen KI-Trainings- und Inferenzaufgaben übertreffen IPU-Systeme die neuesten GPU-basierten Systeme deutlich, da sie auf einer völlig neuen Art von Siliziumarchitektur basieren.
Für groß angelegte Bereitstellungen bietet die IPU-POD-Plattform von Graphcore die Möglichkeit, sehr große Modelle parallel auf einer großen Anzahl von IPU-Prozessoren auszuführen oder die Rechenressourcen für mehrere Benutzer und Aufgaben gemeinsam zu nutzen.
Skalierung von BERT auf Graphcore-Hardware
Die meisten unserer Leser sind wahrscheinlich mit BERT vertraut , dem Bidirectional Encoder Representations from Transformers-Modell, das 2018 von Google veröffentlicht wurde. Im Wesentlichen versteht BERT den Kontext viel besser als frühere unidirektionale Modelle wie Generative Pre-trained Transformers (GPTs). Beispielsweise kennt BERT die Unterschiede zwischen einem Wort wie „run“, das im Englischen viele verschiedene Bedeutungen hat, viel eher. Das liegt daran, dass es in mehrere Richtungen schaut (daher „bidirektional“), um herauszufinden, was „run“ in einem bestimmten Satz bedeutet. Schließlich ist ein „Lauf“ Ihres neuesten Modells etwas ganz anderes als ein „Lauf“ auf dem Laufband.
BERT war so erfolgreich, dass Google es jetzt bei fast jeder englischsprachigen Suche verwendet. Es wurde in unzähligen Kontexten angewendet und war ein Baustein für mehrere SOTA-Ansätze, nicht nur in NLP, sondern auch in so unterschiedlichen Bereichen wie Video, Computer Vision und Proteinmerkmalsextraktion.
BERT ist auch ein ziemlich großes Modell. Die BERT-Basisvariante hat 110 Millionen Parameter, während BERT-large 340 Millionen Parameter hat. Tatsächlich können einige dieser großen Modelle über 100 Milliarden Parameter haben.
Da Modelle wie BERT immer häufiger zum Einsatz kommen, steigt die Nachfrage nach Hardware, die mit der damit verbundenen Rechenleistung Schritt halten kann. Und dieses Problem löst Graphcore mit seinen Intelligence Processing Units (IPUs).
IPUs sind KI-Prozessoren, die für die Verarbeitung groß angelegter Modelle wie BERT und der nächsten Welle noch größerer Modelle konzipiert sind. Normalerweise sind sie in PODs miteinander verbunden, sodass das Training dieser Modelle in einem angemessenen Zeitrahmen von einigen Tagen oder sogar nur wenigen Stunden abgeschlossen werden kann.
Graphcore selbst hat hier ausführlich über seine Prozesse geschrieben . Im Wesentlichen verwenden sie mehrere verbundene IPUs (daher IPU-POD) und verwenden verschiedene datenparallele Modelltrainingstechniken, um die Vortrainingsprozesse auf diese mehreren Maschinen zu skalieren. Wir lassen sie das erklären:
„Beim datenparallelen Training wird der Trainingsdatensatz in mehrere Teile aufgeteilt, die jeweils von einer Modellreplik verwendet werden. Bei jedem Optimierungsschritt werden die Gradienten über alle Repliken hinweg mittelwertreduziert, sodass die Gewichtsaktualisierung und der Modellzustand über alle Repliken hinweg gleich sind.“
Graphcore-Ingenieure verwenden außerdem Gradient Accumulation, um die parallele Skalierungseffizienz beim Training von BERT mit großen Batches aufrechtzuerhalten.
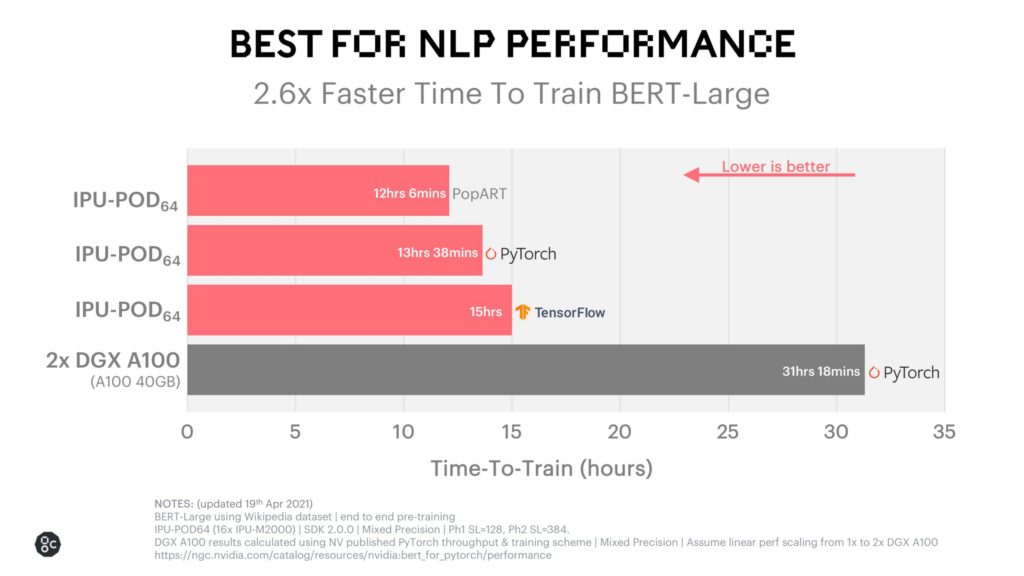
Das Endergebnis ist, dass ihre BERT-Trainingszeiten unglaublich schnell sind: etwas mehr als 12 Stunden auf ihrem eigenen PopART-System. Diese Leistung können Sie unten sehen.
Der Kundenstamm von Graphcore besteht aus intelligenten, innovativen Unternehmen, die große und komplexe Modelle betreiben. Der Ausbau dieser Infrastruktur ist für sie von zentraler Bedeutung, da sie ihre wachsende Benutzerbasis unterstützen. Aber all diese IPUs zu kombinieren und Experimente dieser Größenordnung durchzuführen, ist, gelinde gesagt, eine anspruchsvolle Aufgabe. Hier kommt Weights & Biases ins Spiel.
Skalierung von IPU-Experimenten mit Gewichten und Verzerrungen
Ähnlich wie die IPU-PODs von Graphcore es KI-Ingenieuren ermöglichen, parameterreiche Modelle wie BERT schneller zu trainieren, halfen Weights & Biases dem Team bei Graphcore, seine Experimente zu skalieren.
Vor der Integration mit Weights & Biases-Tools tat Graphcore das, was viele Teams tun: Es erstellte interne Tools und verfolgte seine Experimente manuell in Tabellenkalkulationen.
Dieser Ansatz brachte einige knifflige Herausforderungen mit sich. Zum einen hatten sie Probleme, Experimente sowohl über mehrere IPU-POD-Systeme als auch über mehrere Einsatzorte hinweg zu verfolgen. Mit anderen Worten: Die Skalierung ihres Ansatzes wurde zu kompliziert, um sie effektiv zu verfolgen, und das war ein Problem, da groß angelegte Experimente für die Aktivierung ihrer Zielmodelle für maschinelles Lernen von entscheidender Bedeutung sind. Sie hatten auch keinen zentralen Ort, um ihre Arbeit zu analysieren, oder eine einfache Möglichkeit, teamübergreifend zusammenzuarbeiten und Ergebnisse auszutauschen.
Zu diesen Herausforderungen kommt noch hinzu, dass das Trainieren riesiger Modelle auf mehreren Maschinen eine wirklich komplexe Aufgabe ist. Es können Probleme mit dem Modell selbst, mit den Datensätzen oder mit Fehlern in der Software auftreten, um nur einige mögliche Schwierigkeiten zu nennen. Um diese Fehlerquellen zu diagnostizieren, war eine zentrale Informationsquelle erforderlich, die alle ihre Arbeit aufzeichnen und mit der sie in die Vergangenheit zurückblicken und frühere und aktuelle Experimente vergleichen konnten.
Ihre interne Lösung konnte einige der Probleme bewältigen, aber je komplexer die Arbeit von Graphcore wurde, desto mehr verlangten sie von ihrer internen Lösung. Weights & Biases war eine „offensichtliche Wahl“.
„Wir führen jetzt 50- oder 100-mal mehr Experimente durch als vorher auf den Mk1 IPU-Systemen“, beschrieb es Phil Brown, Director of Applications bei Graphcore.
Mit Weights & Biases können sie ihre Experimente skalieren, während sie die Systeme skalieren, die sie bauen. So können sie schneller herausfinden, was schiefgelaufen ist, sodass es schneller behoben werden kann. Sie erhalten eine zentrale Informationsquelle, die bis zum Tag der Instrumentierung zurückreicht, sodass sie erfolgreiche Durchläufe von vor Monaten vergleichen und neue Erkenntnisse gewinnen können. So können sie erkennen, ob bei diesen Experimenten mit schwankender Leistung zu rechnen ist oder ob ein Problem vorliegt, das behoben werden muss. Und die Visualisierungen gefallen ihnen auch sehr gut.
Was kommt als Nächstes für Graphcore?
Graphcore baut nicht nur weiterhin größere und leistungsfähigere IPUs und IPU-PODs, sondern auch ein Software-Ökosystem . Durch die Instrumentierung von Weights & Biases kann sich das Unternehmen auf die Bereitstellung der Systeme und Software konzentrieren, die seine Kunden benötigen, um jetzt und in Zukunft hochmoderne Modelle zu trainieren, wenn die Modelle noch größer werden.
Denn machen Sie sich nichts vor: Die Modelle werden wachsen. Schätzungen zufolge werden SOTA NLP-Modelle pro Jahr sogar zehnmal größer. Verteilte Berechnungen werden absolut notwendig sein. Und IPUs sind eine hervorragende Wahl, da die Modelle sowohl in Größe als auch Komplexität immer weiter zunehmen.
Wir freuen uns, dass wir einen kleinen Beitrag dazu leisten können, ihnen zu helfen. Wir empfehlen, sich neben der Graphcore-Website auch die ausführliche Fallstudie zu BERT anzusehen .