
「私たちは現在、Mk1 IPU システムで以前に行っていた実験と比較して、50 倍から 100 倍の実験を推進しています。」

フィル・ブラウン
アプリケーション担当ディレクター
この記事では、Graphcore が高度な IPU ハードウェアで実行される実験数の指数関数的な増加を促進するために Weights & Biases がどのように役立ったかを見ていきます。
Graphcoreについて
グラフコア
は、現在および次世代の人工知能ワークロードのニーズに合わせて設計された、世界で最も洗練されたマイクロプロセッサである 知能処理装置 (IPU)
の発明者です。
は、現在および次世代の人工知能ワークロードのニーズに合わせて設計された、世界で最も洗練されたマイクロプロセッサである 知能処理装置 (IPU)
の発明者です。
グラフコア
のシステムは、AI ワークロードを大幅に加速できるだけでなく、イノベーターがより洗練された新しいモデルを開発できるようにします。多くの AI トレーニングおよび推論タスクでは、IPU システムはまったく新しい種類のシリコン アーキテクチャをベースとしているため、最新の GPU ベースのシステムよりも大幅に優れたパフォーマンスを発揮します。
のシステムは、AI ワークロードを大幅に加速できるだけでなく、イノベーターがより洗練された新しいモデルを開発できるようにします。多くの AI トレーニングおよび推論タスクでは、IPU システムはまったく新しい種類のシリコン アーキテクチャをベースとしているため、最新の GPU ベースのシステムよりも大幅に優れたパフォーマンスを発揮します。
大規模な展開の場合、グラフコア
の IPU-POD プラットフォームは、多数の IPU プロセッサで非常に大規模なモデルを並列に実行したり、複数のユーザーやタスク間でコンピューティング リソースを共有したりする機能を提供します。
の IPU-POD プラットフォームは、多数の IPU プロセッサで非常に大規模なモデルを並列に実行したり、複数のユーザーやタスク間でコンピューティング リソースを共有したりする機能を提供します。
グラフコア
のハードウェア上での BERT のスケーリング
読者の多くは、2018 年に Google がリリースした Bidirectional Encoder Representations from Transformers モデルであるBERTをよくご存知でしょう。基本的に、BERT は、Generative Pre-trained Transformers (GPT) などの以前の単方向モデルよりもコンテキストをはるかによく理解します。たとえば、BERT は、英語でさまざまな意味を持つ「run」などの単語の違いを認識する可能性がはるかに高くなります。これは、BERT が複数の方向 (つまり「双方向」) を見て、特定の文で「run」が何を意味するかを理解するためです。結局のところ、最新モデルの「run」は、トレッドミルでの「run」とは大きく異なります。
BERT は成功を収め、Google は今ではほぼすべての英語検索でこれを使用しています。BERT はさまざまなコンテキストに適用されており、NLPだけでなく、ビデオ、コンピューター ビジョン、タンパク質の特徴抽出など、さまざまな分野で複数の SOTA アプローチの構成要素となっています。
BERT もかなり大きなモデルです。BERT-base バリアントには 1 億 1,000 万のパラメータがありますが、BERT-large には 3 億 4,000 万のパラメータがあります。実際、これらの大規模モデルの中には、1,000 億を超えるパラメータを持つものもあります。
現在、BERT のようなモデルの普及が進むにつれて、それに伴うコンピューティングの貪欲さに対応できるハードウェアの需要が高まっています。そして、グラフコア
は、Intelligence Processing Unit (IPU) によってその解決に貢献しています。
は、Intelligence Processing Unit (IPU) によってその解決に貢献しています。
IPU は、BERT のような大規模モデルや、さらに大規模な次世代モデルを処理するために作られた AI プロセッサです。通常、これらは POD で相互に接続されているため、これらのモデルのトレーニングは数日、あるいは数時間という妥当な期間で完了できます。
グラフコア
自身が、ここでそのプロセスについて雄弁に書いています。基本的に、彼らは複数の接続された IPU (つまり IPU-POD) を採用し、さまざまなデータ並列モデルトレーニング手法を使用して、事前トレーニングプロセスをこれらの複数のマシンに拡張します。彼らの説明を見てみましょう。
自身が、ここでそのプロセスについて雄弁に書いています。基本的に、彼らは複数の接続された IPU (つまり IPU-POD) を採用し、さまざまなデータ並列モデルトレーニング手法を使用して、事前トレーニングプロセスをこれらの複数のマシンに拡張します。彼らの説明を見てみましょう。
「データ並列トレーニングでは、トレーニング データセットを複数の部分に分割し、それぞれをモデル レプリカで使用します。各最適化ステップで、すべてのレプリカにわたって勾配の平均が削減されるため、重みの更新とモデルの状態はすべてのレプリカで同じになります。」
グラフコア
のエンジニアは、大規模なバッチで BERT をトレーニングするときに並列スケーリングの効率を維持するために、Gradient Accumulation も使用します。
のエンジニアは、大規模なバッチで BERT をトレーニングするときに並列スケーリングの効率を維持するために、Gradient Accumulation も使用します。
最終結果、BERT のトレーニング時間は信じられないほど速くなりました。独自の PopART システムで 12 時間強です。そのパフォーマンスを以下で確認できます。
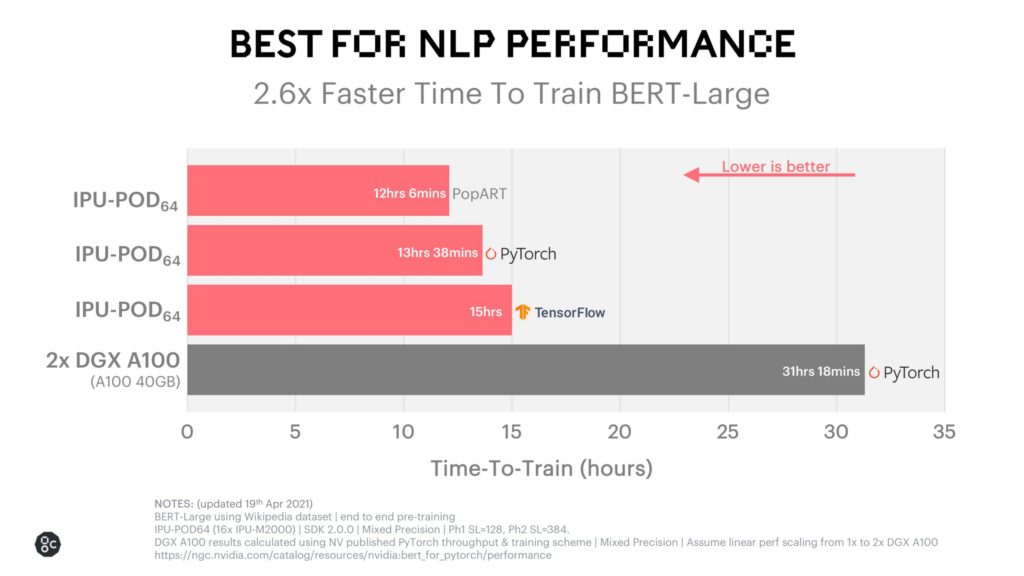
Graphcore の顧客ベースは、大規模で複雑なモデルを実行している、スマートで革新的な企業でいっぱいです。このインフラストラクチャを構築することは、拡大するユーザーベースをサポートする上で、彼らにとって重要です。しかし、これらすべての IPU を組み合わせて、これほど大規模な実験を実行することは、控えめに言っても、困難な作業です。そこで Weights & Biases の出番です。
重みとバイアスによる IPU 実験のスケーリング
Graphcore の IPU-POD によって AI エンジニアが BERT のようなパラメータが豊富なモデルをより速くトレーニングできるようになるのと少し同じように、W&B は Graphcore のチームが実験を拡大するのを支援しました。
Weights & Biases ツールと統合する前、Graphcore は多くのチームが行っていること、つまり内部ツールを構築し、スプレッドシートで実験を手動で追跡する作業を行っていました。
このアプローチには、いくつかの難しい課題がありました。まず、複数の IPU-POD システムと複数の展開場所の両方で実験を追跡する際に問題がありました。言い換えれば、アプローチのスケーリングが複雑になりすぎて効果的に追跡できなくなっていました。大規模な実験は、ターゲットの機械学習モデルを有効にするために不可欠であるため、これは問題でした。また、作業を分析するための中心的な場所も、チーム全体で共同作業して調査結果を共有する簡単な方法もありませんでした。
これらの課題に加えて、複数のマシンで大規模なモデルをトレーニングするのは非常に複雑な作業です。モデル自体、データセット、ソフトウェアのバグなど、潜在的な問題は数多くあります。これらの障害点を診断するには、すべての作業を記録し、時間を遡って以前の実験と現在の実験を比較できる、信頼できる中央ソースが必要でした。
社内ソリューションでいくつかの問題に対処できましたが、Graphcore の作業が複雑になるにつれて、社内ソリューションに求められるものも増えていきました。W&B は「当然の選択」でした。
「Mk1 IPU システムで以前行っていた実験と比べて、現在では 50 倍から 100 倍もの実験を行っています」と、Graphcore のアプリケーション ディレクターである Phil Brown 氏は説明します。
W&B を使用すると、構築中のシステムのスケールアップに合わせて実験をスケールアップできます。何が悪かったのかをより早く簡単に発見できるため、より早く修正できます。インストルメント化した日までさかのぼる真実の中心的な情報源が提供されるため、数か月前の成功した実行と比較して、新しい洞察を得ることができます。これらの実験でパフォーマンスが変動することが予想されるのか、デバッグが必要な問題があるのかを理解できます。また、視覚化も気に入っています。
Graphcore の今後
Graphcore は、より大きく強力な IPU と IPU-POD の開発を継続しているだけでなく、ソフトウェア エコシステムも構築しています。W&B を装備することで、モデルがさらに大規模になった場合でも、顧客が最先端のモデルをトレーニングするために必要なシステムとソフトウェアの提供に集中できるようになります。
間違いなく、モデルは拡大していきます。実際、SOTA NLP モデルは年間 10 倍に拡大していると推定されています。分散コンピューティングは絶対に必要です。また、モデルのサイズと複雑さが拡大し続ける中、IPU は素晴らしい選択肢です。