
自律走行車の認識は、カメラ、 LIDAR、レーダーといった補完的なセンサー方式に依存します。
たとえば、LIDAR は非常に正確な深度を提供しますが、長距離では信号がまばらになる可能性があります。カメラは長距離でも高密度な意味信号を提供できますが、物体の深度を捉えることはできません。
これらのセンサー モダリティを融合することで、それぞれの強みを補完し、単一のセンサー モダリティにのみ依存するよりも正確なエージェント (車、歩行者、自転車など) の 3D 検出を実現できます。自動運転の研究を加速するために、Lyft は自動運転車両からのデータを共有し、認識と予測の問題に取り組んでいます。
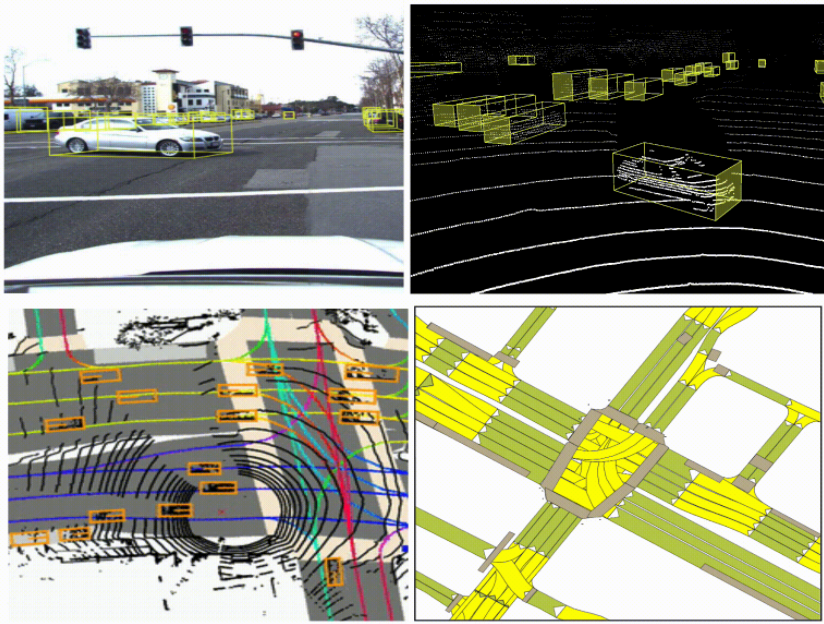
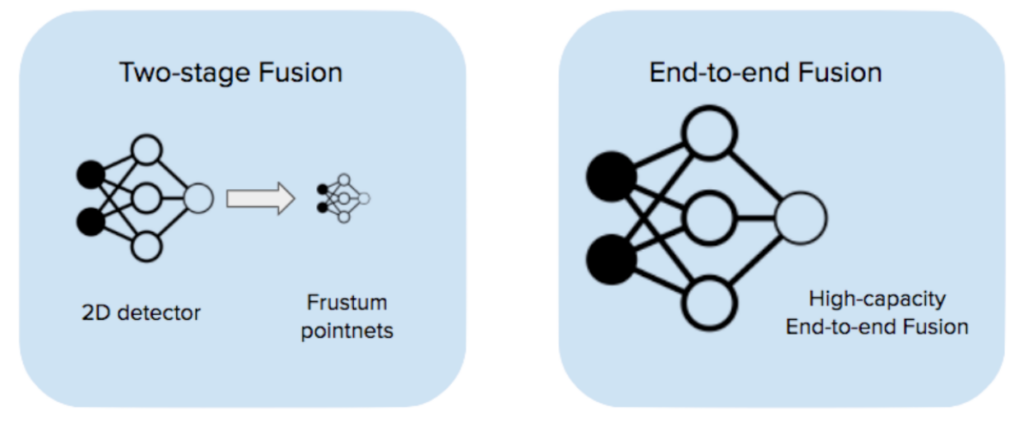
カメラとライダーを融合するための戦略は数多くあります。興味のある読者は、以下のリソース [1-6] でさまざまな融合戦略の包括的なレビューを見つけることができます。ここでは、ディープ ニューラル ネットワークを活用する 2 つの戦略のみを検討します。
1つの戦略は、フラスタムポイントネット[1]のような2段階の融合です。第1段階は、カメラ画像を取得して2D検出を出力する画像検出モデルです。第2段階では、2D検出提案を受け取り、そこから3Dでフラスタムを作成し、各フラスタム内でLIDARベースの検出を実行します。私たちはこの戦略を初期のスタックに採用し、良い結果を達成しました(詳細についてはブログ投稿をご覧ください)。
ただし、2 段階の融合パフォーマンスは、ビジョン モデルまたは LiDAR モデルのいずれかによって制限されます。両方のモデルは単一のモダリティ データを使用してトレーニングされており、2 つのセンサー モダリティを直接補完するように学習する機会はありません。
カメラとライダーを融合する別の方法は、エンドツーエンドの融合 (EEF) です。これは、すべての生のカメラ画像 (この場合は 6 枚) とライダー ポイント クラウドを入力として受け取り、エンドツーエンドでトレーニングする単一の高容量モデルを使用する方法です。モデルは、各モダリティで個別の特徴抽出を実行し、融合された特徴マップで検出を実行します。このレポートでは、エンドツーエンドのカメラとライダーの融合に関する当社の見解について説明し、社内の ML フレームワークである Jadooと W&B を使用して実施した実験結果を紹介します。
エンドツーエンドの融合は2段階の融合よりも優れたパフォーマンスを発揮します
エンドツーエンドでトレーニングされた EEF には、2 段階の融合に比べていくつかの重要な利点があります。
-
画像と LIDAR 機能の融合はモデル内で行われ、トレーニング中にエンドツーエンドで学習されます。つまり、ヒューリスティックとハイパーパラメータが少なくなり、ネットワークは入力から出力までのより複雑なマッピングを学習できるようになります。
-
EEF モデルは、トレーニング中のデータ ドロップアウトにより、どちらのモダリティでもデータの欠落に対してフォールト トレランスになるようにトレーニングできます。比較すると、2 段階モデルで同じレベルのフォールト トレランスを実現するのは困難です。
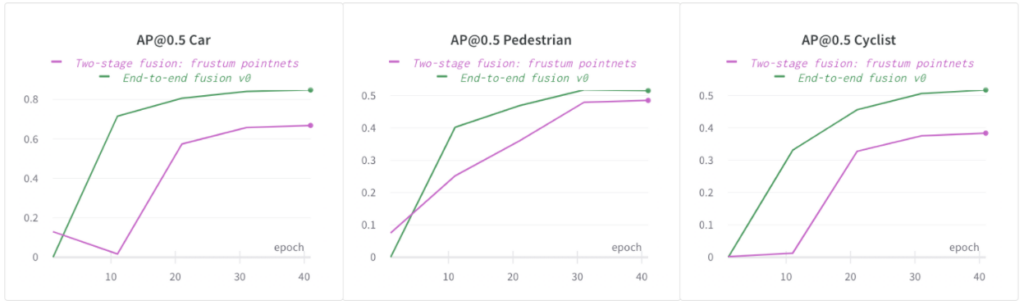
次の図では、エンドツーエンドの融合モデルが、当社の社内データセットにおける自動車、歩行者、自転車の 2 段階融合モデルよりも AP@0.5 がはるかに高いことがわかります。他のクラス (自動車と自転車) でも同じ傾向が見られました 。簡単にするために、レポートの残りのセクションでは歩行者の AP のみを比較します。
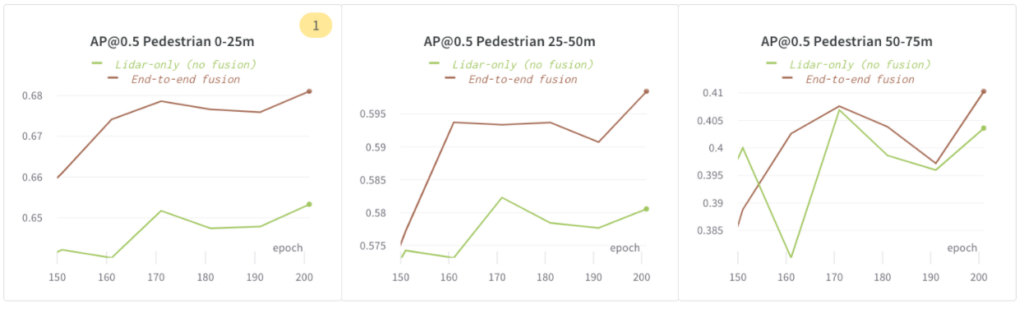
エンドツーエンドの融合は、LiDARのみのモデルよりも優れたパフォーマンスを発揮します
画像の特徴を融合することでモデリングの精度が向上するかどうかを理解するために、この実験を実行しました。次の構成を使用しました。
-
ライダーのみ(融合なし): ライダーのみのモデル
-
エンドツーエンドの融合: 画像とライダーによるエンドツーエンドの学習融合
次の図では、75 メートル範囲内の歩行者の場合、AP@0.5 で「エンドツーエンドの融合」が「Lidar のみ (融合なし)」よりもパフォーマンスが優れていることを示しています。
モデル容量とオーバーフィッティングのバランス
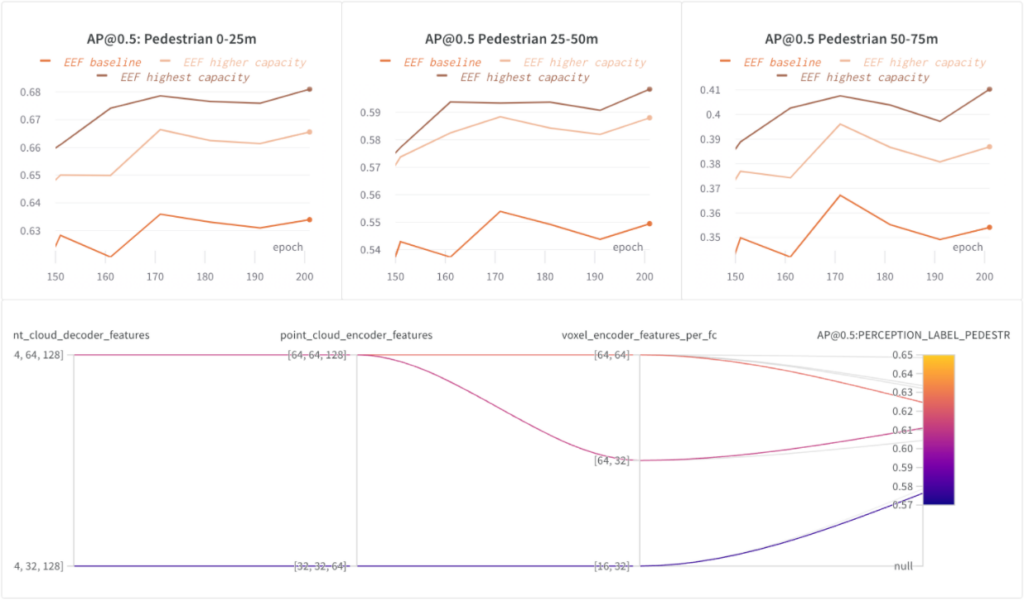
モデル容量の増加 = 精度の向上
EEF モデル内の特徴抽出器の容量を増やし、容量が増加する 3 つの構成 ( EEF ベースライン、EEF 高容量、E EF 最高容量)をトレーニングしました。
次のグラフでは、モデル容量が大きいほど効果があることを示しています。最高のモデル容量 (ポイント クラウド エンコーダー/デコーダー機能の数) により、75 メートル範囲内の歩行者の AP@0.5 が約 5% 向上しました。
データ拡張による過剰適合への対処
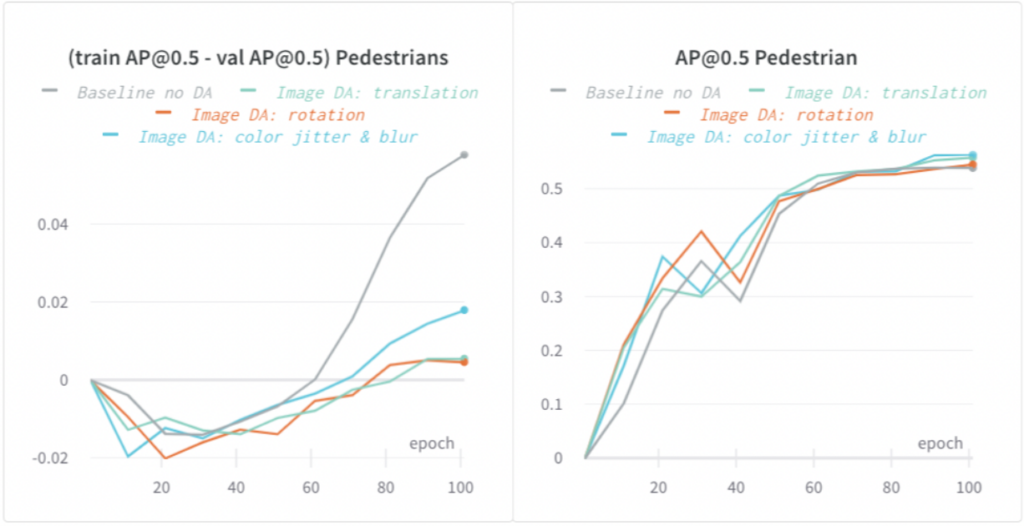
EEF モデルは高容量モデルであり、過剰適合になりやすい傾向があります。過剰適合の兆候の 1 つは、トレーニング メトリックは向上するが、検証メトリックは向上しない (またはトレーニング メトリックと検証メトリック間のギャップが拡大する) ことです。
画像とライダーの両方のデータ拡張 (DA) を適用し、過剰適合を大幅に削減しました。次のグラフでは、さまざまな種類の画像ベースの DA により、歩行者のトレーニング AP と検証 AP @0.5 のギャップが最大 5% 削減され、モデルの一般化が改善されたことが示されています。
より速いトレーニング: 反復速度が重要
画像ドロップアウトと半解像度画像の使用による高速トレーニング
大容量 EEF モデルのトレーニングは、次の理由により遅くなる可能性があります。
-
大容量からの貢献を考慮すると、コンピューティングは大規模です。
-
モデルの GPU メモリ フットプリントが大きい。つまり、トレーニング中に大きなバッチ サイズを使用すると、モデルの GPU メモリが不足しやすくなります。強制的に小さいバッチ サイズを使用すると、トレーニングが遅くなります。
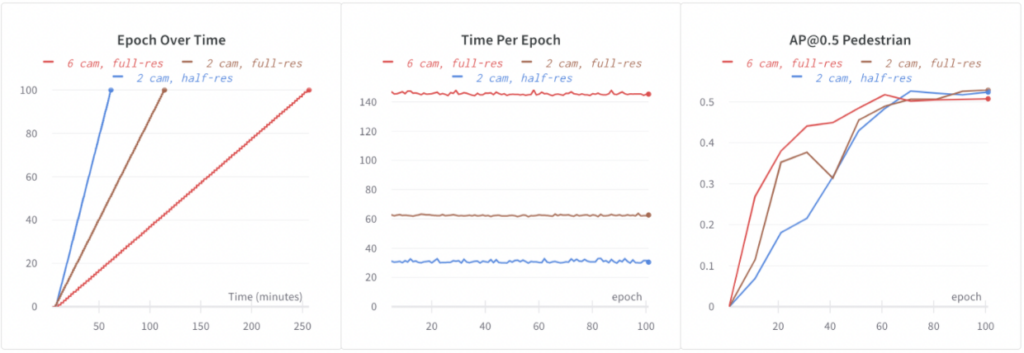
ベースライン EEF は、6 つのフル解像度画像すべてでトレーニングします。64 個の GPU で 100 エポックをトレーニングするのに 4.3 時間かかりました。EEF でより速く反復するには、トレーニングを高速化する必要があります。次の構成で実験しました。
-
6 カメラ、フル解像度: ベースライン EEF。
-
2 台のカメラ、フル解像度: トレーニング中にランダム画像ドロップアウトを使用しました。トレーニング中に 6 枚の画像のうち 4 枚をランダムにドロップアウトしました。これにより、計算時間とデータ読み込み時間が短縮され、トレーニングが 2.3 倍高速化されました。さらに、ドロップアウトは正規化にも役立ち、おそらくこのため、精度が向上しました (以下に示す: 歩行者の場合、+1.5% AP@0.5)。
-
2 台のカメラ、半分の解像度: 半分の解像度の画像を使用することで、画像の解像度をさらに下げました。これにより、精度の低下をほとんど起こさずに、フル解像度の画像を使用する場合よりも 2 倍高速なトレーニングが可能になりました。
画像ドロップアウトと半解像度画像の両方の助けを借りて、EEF トレーニングを 4.3 倍高速化し、モデルの精度も向上しました。
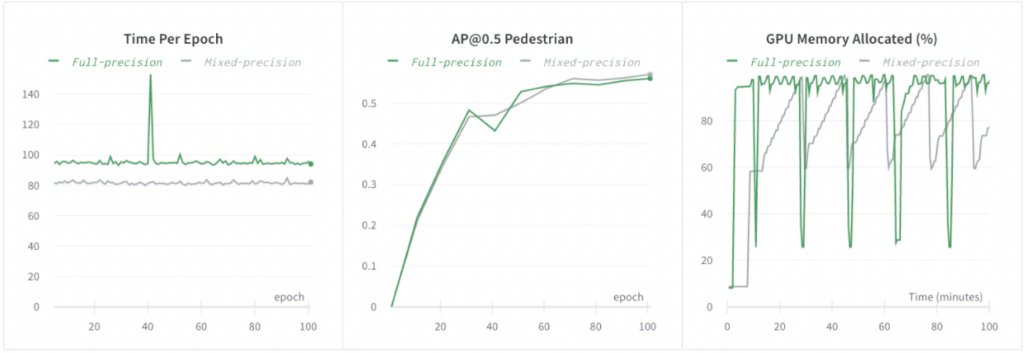
混合精度トレーニング
インパクト
-
大容量のエンドツーエンドの融合は、3D 検出において 2 段階の融合や LIDAR のみのモデルよりも優れたパフォーマンスを発揮することを実証しました。
-
私たちは、大容量モデルをトレーニングし、モデル容量を増やしながら過剰適合を減らし、高速反復速度を維持するワークフローを実証しました。
Lyft レベル 5 について詳しく見る
謝辞
このレポートは、著者と Anastasia Dubrovina、Dmytro Korduban、Eric Vincent、Linda Wang による研究に基づいています。