
Die Wahrnehmung autonomer Fahrzeuge hängt von komplementären Sensormodalitäten ab: Kamera, Lidar und Radar.
Lidar liefert beispielsweise sehr genaue Tiefendaten, kann aber auf lange Distanzen unzureichend sein. Kameras können auch auf lange Distanzen dichte semantische Signale liefern, erfassen aber nicht die Tiefe eines Objekts.
Durch die Verschmelzung dieser Sensormodalitäten können wir ihre komplementären Stärken nutzen, um eine genauere 3D-Erkennung von Agenten (z. B. Autos, Fußgänger, Radfahrer) zu erreichen, als wenn wir uns nur auf eine einzige Sensormodalität verlassen würden. Um die Forschung zum autonomen Fahren zu beschleunigen, teilt Lyft Daten aus unserer autonomen Flotte, um Wahrnehmungs- und Vorhersageprobleme zu lösen .
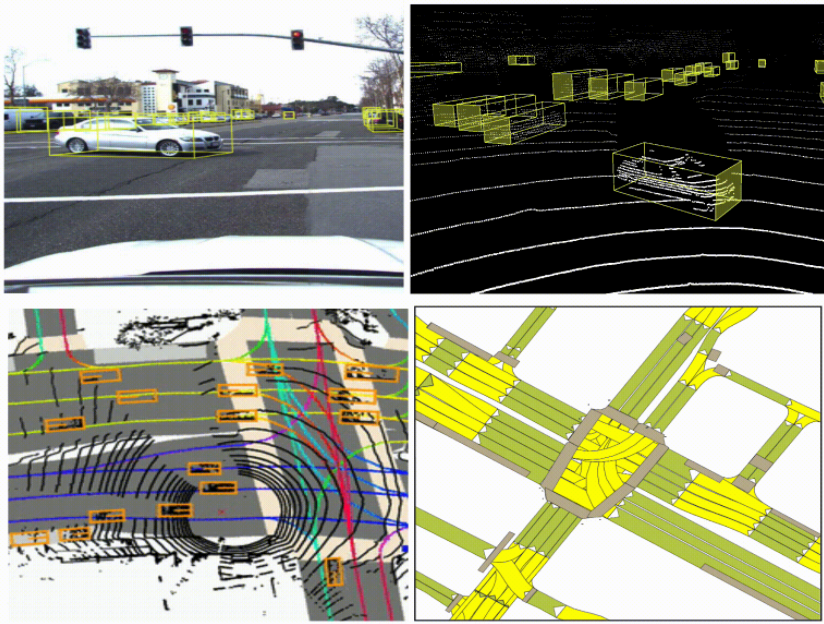
Es gibt viele Strategien zur Fusion von Kameras und Lidar. Interessierte Leser finden unten in den Ressourcen [1-6] einen umfassenden Überblick über verschiedene Fusionsstrategien. Hier betrachten wir nur zwei Strategien, die beide tiefe neuronale Netzwerke nutzen.
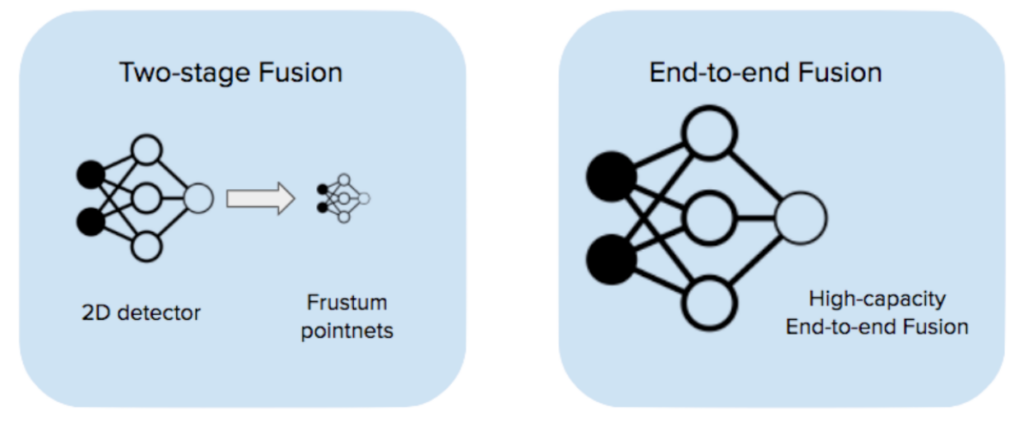
Eine Strategie besteht in der zweistufigen Fusion, ähnlich wie bei Frustum-Pointnets [1] : Die erste Stufe ist ein Bilderkennungsmodell, das Kamerabilder aufnimmt und 2D-Erkennungen ausgibt. Die zweite Stufe nimmt die 2D-Erkennungsvorschläge, erstellt daraus 3D-Frustums und führt innerhalb jedes Frustums eine Lidar-basierte Erkennung durch. Wir haben diese Strategie in unserem frühen Stack übernommen und gute Ergebnisse erzielt ( weitere Einzelheiten finden Sie in unserem Blog-Beitrag ).
Die Leistungsfähigkeit der zweistufigen Fusion wird jedoch entweder durch das Bildverarbeitungsmodell oder das Lidar-Modell eingeschränkt. Beide Modelle werden mit Daten einer einzigen Modalität trainiert und haben keine Chance, zu lernen, die beiden Sensormodalitäten direkt zu ergänzen.
Eine alternative Möglichkeit, Kamera und Lidar zu fusionieren, ist die End-to-End-Fusion (EEF): Dabei wird ein einziges Modell mit hoher Kapazität verwendet, das alle Rohkamerabilder (in unserem Fall 6 Stück) und Lidar-Punktwolken als Eingabe verwendet und End-to-End trainiert. Das Modell führt separate Feature-Extraktoren für jede Modalität aus und führt die Erkennung auf der fusionierten Feature-Map durch. In diesem Bericht werden wir unseren Ansatz zur End-to-End-Kamera-Lidar-Fusion erörtern und experimentelle Ergebnisse präsentieren, die mit Jadoo, unserem internen ML-Framework , und Weights & Biases durchgeführt wurden.
End-to-End-Fusion ist leistungsfähiger als zweistufige Fusion
End-to-End-trainiertes EEF bietet gegenüber der zweistufigen Fusion mehrere entscheidende Vorteile:
-
Die Verschmelzung von Bild- und Lidar-Funktionen erfolgt innerhalb des Modells und wird während des Trainings durchgängig erlernt. Dies bedeutet weniger Heuristiken und Hyperparameter und das Netzwerk hat die Kapazität, komplexere Zuordnungen von der Eingabe zur Ausgabe zu erlernen.
-
EEF-Modelle können so trainiert werden, dass sie fehlertolerant gegenüber fehlenden Daten in beiden Modalitäten sind, da während des Trainings Daten verloren gehen. Im Vergleich dazu ist es für zweistufige Modelle schwieriger, das gleiche Maß an Fehlertoleranz zu erreichen.
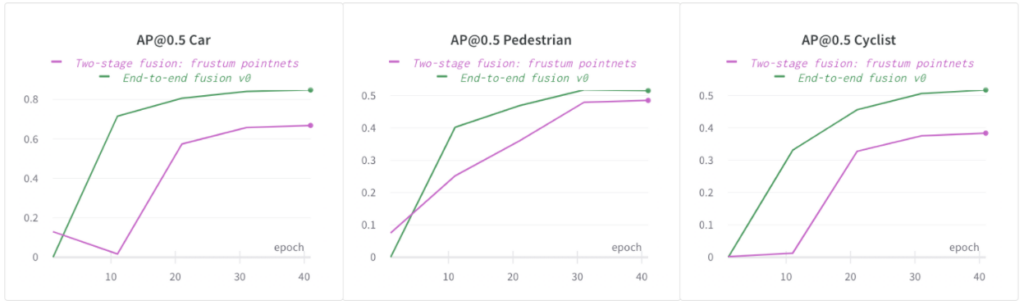
End-to-End-Fusion ist leistungsfähiger als ein reines Lidar-Modell
Wir haben dieses Experiment durchgeführt, um herauszufinden, ob die Modellgenauigkeit durch die Fusion von Bildmerkmalen erhöht wird. Wir haben die folgenden Konfigurationen verwendet:
-
Nur Lidar (keine Fusion): Nur-Lidar-Modell
-
End-to-End-Fusion: End-to-End-Fusion mit Bild und Lidar
In den folgenden Abbildungen haben wir gezeigt, dass die „End-to-End-Fusion“ bei Fußgängern im Umkreis von 75 m bei AP@0,5 eine bessere Leistung erzielt als „Nur Lidar (keine Fusion)“.
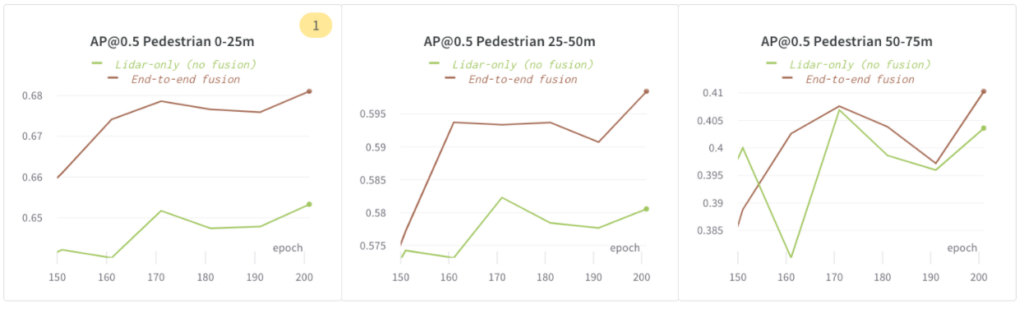
Ausgleich von Modellkapazität und Überanpassung
Höhere Modellkapazität = Verbesserte Genauigkeit
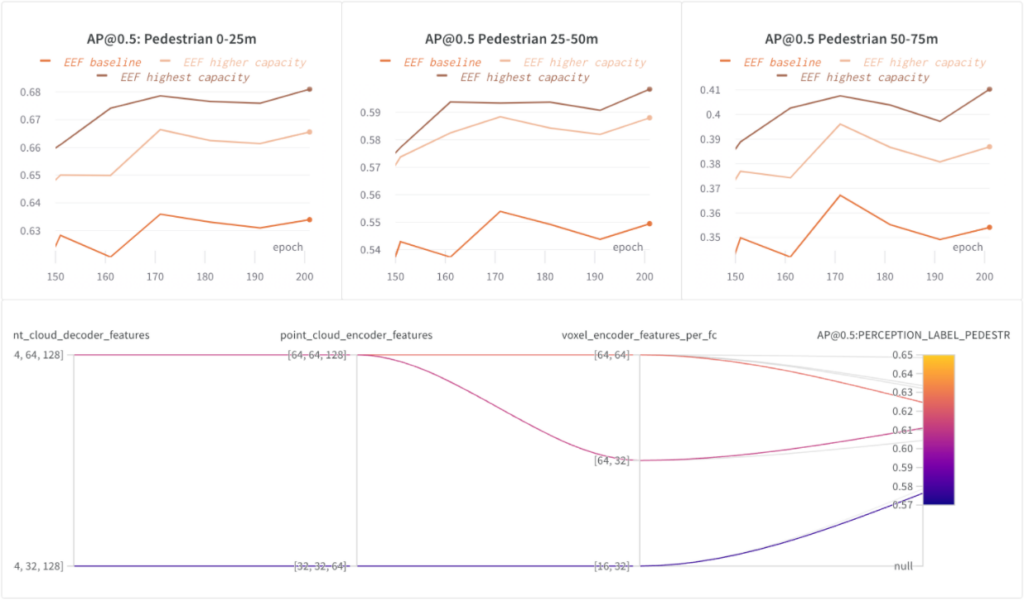
Wir haben die Kapazität der Merkmalsextraktoren innerhalb des EEF-Modells erhöht und drei Konfigurationen mit zunehmender Kapazität trainiert: EEF-Baseline, EEF – höhere Kapazität und EEF – höchste Kapazität .
In den folgenden Grafiken haben wir gezeigt, dass eine höhere Modellkapazität hilfreich ist. Die höchste Modellkapazität (in Bezug auf die Anzahl der Punktwolken-Encoder-/Decoderfunktionen) steigerte AP@0,5 für Fußgänger im Umkreis von 75 m um ~5 %.
Overfitting mit Datenerweiterungen bekämpfen
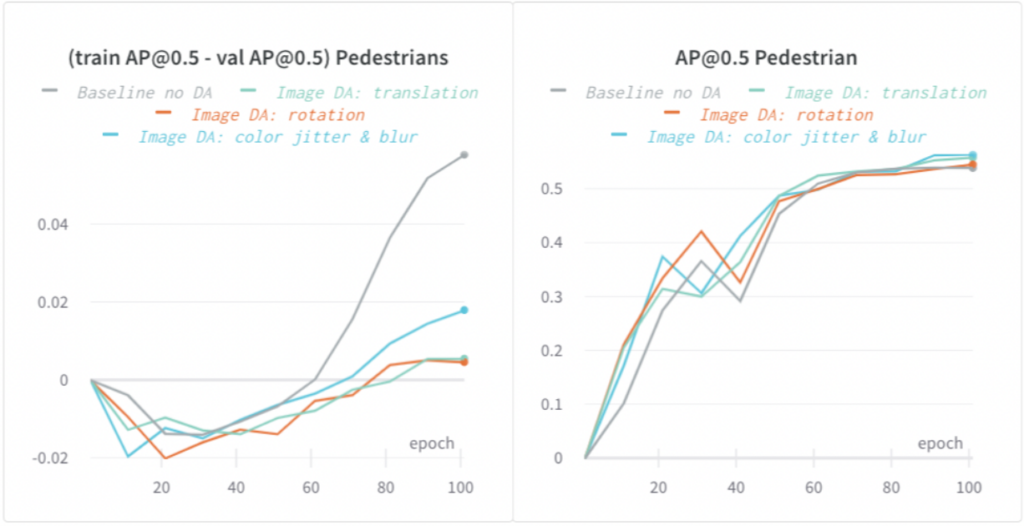
Das EEF-Modell ist ein Modell mit hoher Kapazität und neigt eher zu Überanpassung. Ein Anzeichen für Überanpassung ist, dass sich die Trainingsmetrik verbessert, während sich die Validierungsmetrik nicht verbessert (oder eine größere Lücke zwischen Trainings- und Validierungsmetrik).
Wir haben sowohl Bild- als auch Lidar-Datenerweiterungen (DA) angewendet und die Überanpassung deutlich reduziert. In den folgenden Grafiken haben wir gezeigt, dass verschiedene Arten bildbasierter DA die Lücke zwischen Trainings- und Validierungs-AP @0,5 für Fußgänger um bis zu 5 % reduziert und die Modellgeneralisierung verbessert haben.
Schnelleres Training: Auf die Iterationsgeschwindigkeit kommt es an
Schnelleres Training durch Bildausfälle und Verwendung von Bildern mit halber Auflösung
Das Training des EEF-Modells mit hoher Kapazität kann aus folgenden Gründen langsam sein:
-
Unter Berücksichtigung der Beiträge der Hochkapazität ist die Rechenleistung groß.
-
Der GPU-Speicherbedarf des Modells ist groß. Dies bedeutet, dass das Modell bei Verwendung einer großen Batchgröße während des Trainings eher dazu neigt, dass der GPU-Speicher knapp wird. Die erzwungene Verwendung einer kleineren Batchgröße bedeutet langsameres Training.
-
Angesichts der großen Eingabemenge (6 Kamerabilder in voller Auflösung + Lidar-Spin, weitere Einzelheiten finden Sie in unserem Lyft Level 5 Open Dataset ) dauert das Laden der Daten einige Zeit.
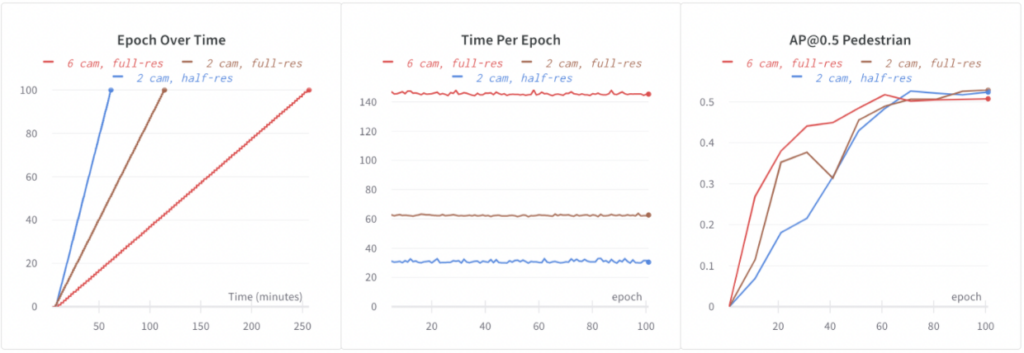
Basis-EEF-Trainings auf allen 6 Bildern in voller Auflösung. Es dauerte 4,3 Stunden, um 100 Epochen auf 64 GPUs zu trainieren. Um schneller auf EEF zu iterieren, müssen wir das Training beschleunigen. Wir haben mit den folgenden Konfigurationen experimentiert:
-
6 Kameras, volle Auflösung: Baseline EEF.
-
2 Kameras, volle Auflösung: Während des Trainings wurde zufälliges Bild-Dropout verwendet: Wir haben während des Trainings zufällig 4 von 6 Bildern gelöscht. Dies reduzierte die Rechen- und Datenladezeit und führte zu einem 2,3-mal schnelleren Training. Darüber hinaus half das Dropout bei der Regularisierung, und wahrscheinlich deshalb haben wir bessere Genauigkeiten beobachtet (unten dargestellt: +1,5 % AP@0,5 für Fußgänger).
-
2 Kameras, halbe Auflösung: Wir haben die Bildauflösung weiter reduziert, indem wir Bilder mit halber Auflösung verwendet haben. Dies führte außerdem zu einem doppelt so schnellen Training als bei Verwendung von Bildern mit voller Auflösung, ohne dass die Genauigkeit wesentlich zurückging.
Mithilfe von Bild-Dropout und Bildern mit halber Auflösung haben wir das EEF-Training um das 4,3-fache beschleunigt und auch die Modellgenauigkeit verbessert.
Training mit gemischter Präzision
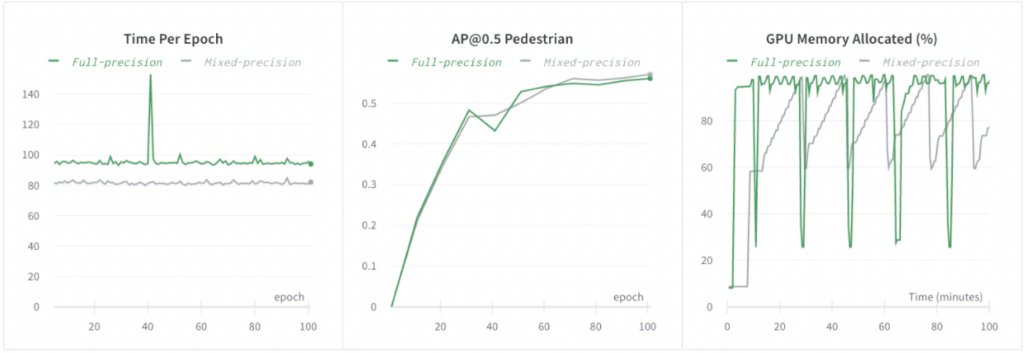
Wir haben die automatische gemischte Präzision von PyTorch verwendet und das Training um das 1,2-fache beschleunigt sowie den GPU-Speicherbedarf reduziert, ohne die Modellgenauigkeit zu beeinträchtigen.
Auswirkungen
-
Wir haben gezeigt, dass die End-to-End-Fusion mit hoher Kapazität bei der 3D-Erkennung bessere Leistungen erbringt als die zweistufige Fusion oder reine Lidar-Modelle.
-
Wir haben unseren Arbeitsablauf beim Trainieren von Modellen mit hoher Kapazität demonstriert, indem wir Überanpassung reduziert, gleichzeitig die Modellkapazität erhöht und eine schnelle Iterationsgeschwindigkeit beibehalten haben.
Erfahren Sie mehr über Lyft Level 5
Danksagung
Dieser Bericht basiert auf der Arbeit der Autoren und Anastasia Dubrovina, Dmytro Korduban, Eric Vincent und Linda Wang.