
The stages of an MLOps pipeline follow the natural lifecycle of a model. What makes a mature pipeline different from an ad-hoc process is not the stages themselves but that each one is defined, automated, and observable.

![]()
Every model failure, traced back far enough, leads to a data problem that the MLOps pipeline failed to catch. Wrong schema accepted silently. A source that changed its timestamp format three months ago. Training data filtered differently from what production would see.
The first stage of an ML pipeline ingests and curates data from operational systems, event streams, and data warehouses into versioned, auditable datasets. This is where the pipeline picks up from where the data pipeline leaves off.
One failure mode that passes all standard data quality checks is temporal leakage. In time-sensitive prediction tasks (churn, fraud, demand), a feature computed over a 30-day lookback window might accidentally include data from after the prediction date if the pipeline’s timestamp logic has a bug. The model trains on features it would not have at inference time, achieves strong offline metrics, and fails in production.
Point-in-time correctness means every feature is computed using only the data that existed at the prediction timestamp. Feature stores enforce this by design. Building it into ad-hoc pipelines retroactively is significantly harder, which is why data ingestion is worth engineering properly the first time.
![]()
Feature engineering transforms raw fields into the inputs a model can use. It is also where the training-serving skew problem originates and needs to be solved.
A production feature pipeline must serve two fundamentally different interfaces. The offline interface handles training: it operates in batch, accesses months of historical data, and must be point-in-time correct. The online interface handles inference: it operates on a single record, must return in milliseconds, and serves from a low-latency store. Teams that build one interface without the other hit predictable problems: a batch-only pipeline cannot support real-time serving; an online-only pipeline cannot generate point-in-time correct training sets. The two interfaces require different infrastructure but must produce numerically identical values for any given input. Any divergence is training-serving skew.
Feature importance drift is an underused early warning signal. If the features the model weights most heavily start shifting in distribution before the model’s aggregate accuracy visibly drops, you get a leading indicator of coming degradation rather than a lagging one. Tracking feature importance across training runs and comparing feature distributions at training time against those at inference time gives teams a head start.
![]()
Training is the stage most people visualize when they think of ML work: experiments, hyperparameter tuning, loss curves. What organizations consistently underestimate is the infrastructure required to make training reproducible and comparable at scale.
The CACE principle from Sculley et al. (2015) — Changing Anything Changes Everything — explains why experiment isolation matters more in ML than in standard software. In an ML system, changing an input signal, a feature’s computation, a sampling strategy, or a data preprocessing step can change model behavior across distribution slices in ways that are hard to detect and harder to attribute. Two experiments are only meaningfully comparable if all unintentional variables are held constant. Without systematic tracking, you are often not measuring the effect of your intended change.
Sculley et al. also identified undeclared consumers as a specific ML debt pattern: other systems that depend on a model’s outputs without the producing team’s knowledge. As models are used more broadly, their outputs become implicit inputs to other pipelines. A change that improves the primary model may silently break a downstream consumer. Dependency documentation and versioned model APIs are the structural solution.
![]()
Statistical accuracy on a held-out test set is necessary for promoting a model to production. It is not sufficient.
Goodhart’s Law states that when a measure becomes a target, it ceases to be a good measure. In ML, this manifests as models that optimize for the logged metric in ways that do not translate to business value: a recommender system that maximizes click-through rate by surfacing clickbait, or a fraud model that achieves 99.9% accuracy by predicting ‘not fraud’ for everything in a class-imbalanced dataset. The practical defense is a multi-metric evaluation with pre-committed thresholds, set before training begins rather than tuned to match whichever model was just trained.
The ML Test Score rubric from Breck et al. (2017) formalizes this. It’s 28 tests across four categories, including checks that the model performs consistently on important data slices, that it outperforms a simple baseline, that training is deterministic for debugging, and that the evaluation infrastructure itself is tested. These tests belong in automated validation gates, not in monthly review meetings.
Shadow mode deployment is an underused pre-production validation technique. The candidate model runs in the production environment, but its outputs are logged and not served to users. Production traffic is duplicated: the live model serves responses while the shadow model processes an identical copy and records its predictions. This gives the candidate model its first exposure to real data distributions, real latency constraints, and real edge cases before it affects anyone.
![]()
Deployment is where ML engineering and software engineering collide, and where organizational friction peaks. Application teams own the services. ML teams own the models. The handoff (‘here is a model artifact, please integrate it’) is often the weakest link, especially when there is no standard for how models are packaged or versioned.
AWS documents a combined shadow-and-canary pattern in their end-to-end MLOps pipeline reference: the shadow model processes a copy of live traffic while the canary model serves a small percentage of users. The combination gives two independent signals before full rollout: production data behavior (shadow) and real user impact (canary).
Canary analysis for ML differs from standard software canary releases in one important way: the success criterion is not just service health (latency, error rate) but model quality metrics (prediction distribution, confidence calibration, outcome agreement with the champion model). Statistical significance testing on prediction distributions distinguishes real behavioral differences from noise before traffic increases.
![]()
Most organizations treat monitoring as optional, only to regret it later. Vela et al. found temporal degradation in 91% of model-dataset combinations tested. Models degrade by default. Monitoring is what changes the default outcome.
Treating all three identically works for covariate drift but misses concept drift until the damage is significant. Diagnosing which type is occurring before choosing a response is a material operational improvement.
The Population Stability Index (PSI) is one of the most widely used drift metrics. It measures the divergence between the training distribution and the current serving distribution for a given feature. Industry-standard thresholds: PSI below 0.1 is stable; 0.1 to 0.2 warrants investigation; above 0.2 indicates significant drift and should trigger retraining. These are rules of thumb, not statistically derived absolutes — feature importance moderates how aggressively a given PSI value should be treated.
The right-censoring problem in feedback loops is less discussed but equally important. When a model’s decisions determine which outcomes are observed — a loan model that only sees repayment behavior for approved applicants, a content moderation model that only has labels for flagged content — the feedback loop is structurally biased. Retraining on observed outcomes alone encodes the model’s own past decisions into its future behavior. Solutions include counterfactual logging, inverse propensity weighting, and randomized exploration (occasionally approving near-miss cases to observe outcomes that would otherwise be invisible).
The building blocks of a modern machine learning pipeline architecture are consistent across cloud providers, even if the product names differ. The gap in most organizations is not missing components — it is missing integration and missing metadata.
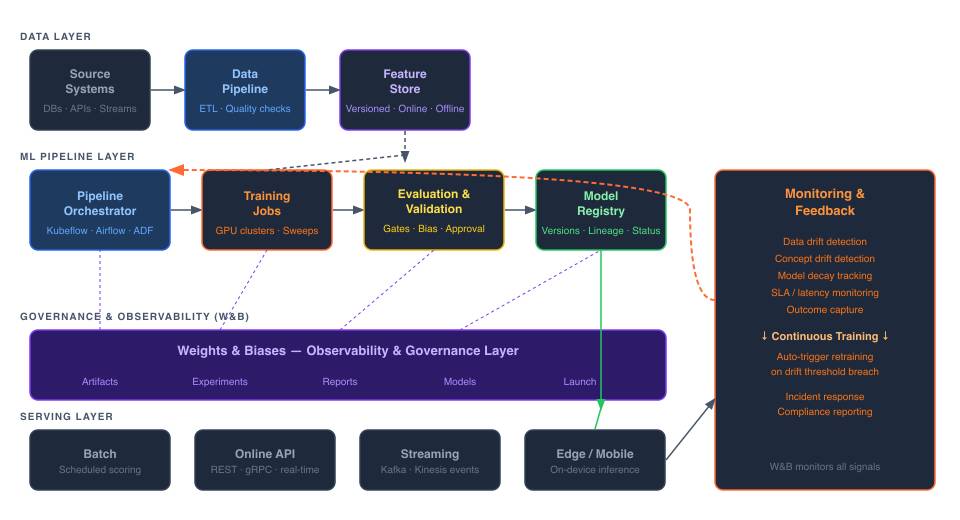
| Layer | What It Contains and Why It Matters |
|---|---|
| Data Layer | Source systems, ETL pipelines, and feature store. The feature store’s offline API provides point-in-time correct training data; its online API serves the same feature logic at inference time. This dual-API design is the architectural solution to training-serving skew. |
| Orchestration Layer | Workflow engine (Airflow, Kubeflow, Azure Data Factory, SageMaker Pipelines) that runs pipeline steps in order, handles retries, and manages dependencies between stages. |
| Experiment and artifact layer | Runs, parameters, datasets, model versions, and lineage. This is the metadata graph: a first-class architectural component that links every production model to its training run, dataset version, and feature definitions. |
| Release layer | Validation rules, approval gates, model registry, packaging, and deployment automation. The registry is the control point that turns ML delivery into a managed process. |
| Observability layer | Drift monitoring, prediction distribution tracking, latency and throughput metrics, audit trails, and retraining triggers. W&B operates across both the layer and the experiment/artifact layers as a unified governance surface. |
Google Vertex AI, Amazon SageMaker Pipelines, and Azure Machine Learning pipelines each implement these layers with different managed services but share the same architectural logic. The key insight is that the lineage graph — the metadata connecting every artifact to the run that produced it — is not a reporting feature. It is the operational foundation of reproducibility, debugging, and compliance.
The 5% ML code finding from Sculley et al. is widely cited, but its implication is less often acted on: if the model is 5% of the system, optimizing only the model while leaving the 95% unmanaged is a category error. The research paper identified specific technical debt patterns that explain where much of that 95% goes.

These patterns do not emerge from bad engineering. They emerge from the normal pace of ML experimentation applied to systems that were never designed for production scale. The full catalog is in the Sculley et al. (2015) paper. MLOps platforms and shared pipeline infrastructure reduce accumulation by making the hidden visible: tracked artifacts, versioned components, and automated validation make each of these debt patterns detectable before they compound.