
For more information or if you need help retrieving your data, please contact Weights & Biases Customer Support at support@wandb.com
AI agents are rapidly transforming the healthcare landscape, ushering in a new era of innovation and efficiency. These intelligent tools, capable of processing vast amounts of medical data and learning from complex patterns, are redefining how care is delivered to patients and managed by providers. By integrating AI agents into healthcare systems, hospitals and clinics can harness advanced decision-making support, enabling clinicians to make faster, more accurate diagnoses and create personalized treatment plans tailored to each patient’s unique needs.

For patients, AI agents promise a more proactive and connected healthcare experience; reminding them of important checkups, monitoring their well-being in real time, and prompting early interventions before problems escalate. Healthcare providers, on the other hand, benefit from reduced administrative burdens, enhanced data-driven insights, and greater operational efficiency across their practices. From streamlining scheduling and claims processing to flagging potential medical errors and suggesting next steps, AI agents are poised to revolutionize the delivery and management of healthcare. As the adoption of AI becomes more widespread, its intelligent integration within electronic health records and healthcare workflows holds the potential to dramatically improve outcomes, patient satisfaction, and the overall quality of care.
AI agents are on the verge of fundamentally advancing nearly every aspect of patient care and medical research. While these capabilities are not yet implemented widely, the technology is fast approaching a level where these once aspirational examples become reality.
AI agents can play a crucial role as a safety net for healthcare providers. Imagine a situation where a patient visits their physician with vague symptoms like fatigue and mild shortness of breath. Even the most experienced doctors may occasionally overlook necessary diagnostic steps for less common conditions.
Here, an AI agent, integrated into the EHR, can review the physician’s notes in real time. If key diagnostic tests—such as a ferritin level to assess for anemia or an age-appropriate cancer screening—are missing, the AI flags this immediately and prompts the clinician to consider these additional options.
The following Python code illustrates how an AI assistant can review clinical notes and lab results to identify potentially missed diagnostic steps and generate appropriate alerts. It also shows how the AI can translate complex medical information into plain language for patients, empowering them to understand their health better.
After running this script, you can visualize how your model is responding within the Weave dashboard. Weave is a powerful tool that helps developers track, visualize, and evaluate their AI agents and language model applications. It captures many important details about the agent, including the prompts sent to the model, the responses received, and any tools the agent uses. This allows you to inspect the agent’s reasoning, debug issues, and ensure it’s performing as expected, offering crucial transparency for high-stakes applications like healthcare.
Still, integrating such safety measures into daily clinical workflows is not trivial. Excessive alerts can lead to “alarm fatigue,” making clinicians less likely to take warnings seriously. Legal questions about who is ultimately responsible for following up on these recommendations also remain unresolved.
The shift toward personalized diagnostics is becoming possible thanks to AI’s ability to process diverse streams of health data. Wearable devices, for instance, are now capable of tracking heart rhythms, sleep quality, HRV, and changes in activity. AI agents can analyze this information and identify early red flags, such as arrhythmias or sleep apnea, often before a patient is even aware of a problem. If a smartwatch detects an unusual heart rhythm at night, the AI agent can immediately notify both the patient and their care team, potentially preventing complications like stroke.
Genetics is becoming more precise and actionable thanks to AI. Software like Emedgene analyzes a patient’s genetic sequencing data to quickly identify disease-causing mutations, helping diagnose rare genetic conditions that might otherwise be missed. Another breakthrough is DeepMind’s AlphaFold, which predicts how genetic sequences fold into protein structures – this is crucial because misfolded proteins often cause diseases, and understanding their shape helps scientists develop targeted treatments.
These AI tools scan through genetic variants and match them against databases of known mutations, helping doctors flag specific risks and develop more targeted screening and prevention plans. For instance, if the analysis reveals mutations linked to increased cancer risk, doctors can implement personalized monitoring schedules instead of following one-size-fits-all guidelines. The real power of AlphaFold lies in drug development and understanding disease mechanisms – by accurately predicting protein structures, it helps researchers understand how genetic mutations affect protein function and develop more effective treatments
Imaging also has huge potential to benefit from AI. With access to full-body MRI data, the agent can scan for early signs of tumors or other changes. Humans are capable of doing this task, however the reality is that it is prohibitively expensive for many. AI agents can also consider multiple tests over a long time period, and intelligently recommend further investigation based on trends rather than relying solely on isolated test results or subjective human interpretation. The advantage AI brings to imaging is its ability to detect subtle changes that might go unnoticed and to synthesize patterns across time and different modalities. Instead of a doctor looking at a single MRI scan in isolation, an AI system can compare scans from months or years apart, noticing gradual but significant trends.
However, deploying these capabilities presents challenges. Algorithms are only as fair and accurate as the data used to train them, and there is a real risk of AI perpetuating existing health disparities if datasets lack diversity. Integrating information from a variety of devices and health records raises significant questions about data standardization and patient privacy, requiring robust safeguards for personally identifiable information (PII).
Many of the limitations in medical research stem from the sheer number of experiments required to fully understand complex biological processes and validate new treatments. Traditional research workflows can be slow, labor-intensive, and constrained by human time and resources. AI-driven robots are beginning to automate complex tasks in research laboratories and clinical diagnostics. For example, robotic arms, steered by AI, have enabled the rapid testing of thousands of drug combinations, accelerating discovery while minimizing human error. This high-speed, high-precision automation not only increases throughput but also enhances reproducibility.
This concept – turning the physical world into a software development kit– will extend to diagnostics, too. Imagine a laboratory where sample handling, experiment execution, and even interpretation of results are seamlessly automated using a fusion of robotics and AI. This could democratize access to sophisticated testing, especially in remote or resource-limited settings. Currently, doctors have to essentially make decisions while also considering patient costs, which inevitably will lead to situations where tests must be skipped in cases where financial constraints limit diagnostic options.
Overall, these advances still require significant investment, meticulous calibration, and rigorous oversight to ensure quality and safety. A malfunction or systematic error in an automated process could scale rapidly if not properly monitored. Validation, standards-setting, and regular audits become critical when physical processes are handled predominantly by machines.
While the potential for AI in healthcare is enormous, it comes with important challenges. Bias remains a serious concern – algorithms trained on incomplete or non-representative data can perpetuate or worsen health inequities. Patient privacy is paramount, especially as more-sensitive data from wearables, genetics, and imaging gets integrated; strong data governance and security protocols are essential.
There are also important questions about trust and accountability. For clinicians and patients to embrace AI-driven recommendations, these systems must be transparent, explainable, and clinically validated. Regulatory hurdles remain, with healthcare leaders and policymakers rightly demanding a high bar for evidence, safety, and ethical safeguards.
Ultimately, the next few years will be pivotal. If these technological and ethical challenges can be resolved, AI agents will not only optimize operational efficiency and safety but truly transform the practice and science of medicine, delivering more precise, responsive, and personalized care to patients everywhere.
Integrating AI agents with Electronic Health Records (EHRs) unlocks a powerful new dimension in both individual patient care and population health. Unlike traditional EHRs, which mainly function as digital filing cabinets, EHRs powered by AI become predictive, interactive, and intelligent clinical partners.
A key advantage is the potential for early disease detection and proactive intervention. AI agents, trained on vast amounts of anonymized EHR data spanning tens or hundreds of thousands of patients, can surface subtle health trends and early warning signs that are impossible for humans to detect at scale. For example, AI might analyze vital signs, lab results, and prior visit notes to alert a primary care physician about a patient’s increased risk for heart failure or diabetes, months before symptoms appear.
By reviewing millions of prior outcomes, LLM-powered agents are adept at spotting correlations that can inform current treatment choices. If a patient is eligible for several different medications, an AI agent can highlight which drug, based on real-world historic data within the EHR, has tended to yield the best outcomes for people with similar profiles and co-existing conditions. This means clinicians are empowered to make evidence-based choices in situations where the “best” option is not obvious.
AI-powered EHR integration also shines in closing care gaps. For example, when reviewing chart notes, a well-trained AI might recognize that certain diagnostic tests—such as a screening colonoscopy or HbA1c check for diabetes have not been performed, even though guidelines or comparable patient cases suggest they should be. The agent can flag these missing tests and prompt clinicians to consider them. Similarly, if prior patient records show that a rarely ordered test helped diagnose a hard-to-detect disease, AI can suggest ordering it in similar new cases.
Beyond supporting physicians, AI is positioned to enhance patient engagement and safety. The agent can translate complex test results or trends into actionable, plain-language prompts. For instance, after bloodwork, a patient might receive a message: “Your liver enzymes are higher than last year. Ask your doctor about whether a follow-up test or a medication review is recommended.” This encourages patients to play a more active role in their health and addresses issues promptly.
For healthcare providers, the integration of AI into EHRs ultimately reduces cognitive burden, helps prevent missed diagnoses, and supports more precise, individualized care planning. For patients, it means earlier warnings, clearer communication, and an overall higher standard of care. As these systems continue to mature, both clinicians and patients will benefit from recommendations and insights that draw on the collective intelligence of millions of medical experiences unlocking a new era of data-driven, proactive healthcare.
One of the biggest challenges facing Western healthcare systems—including those in the United States—is the overwhelming administrative burden that inflates costs and distracts from direct patient care. Much of the healthcare dollar, sometimes as much as 25% in the U.S., goes toward paperwork, billing, insurance claims, appointment management, and other back-office functions. AI agents are positioned to revolutionize this side of medicine, automating repetitive processes, increasing efficiency, and freeing up valuable human resources for what truly matters: patient outcomes.
AI agents can monitor electronic health records and administrative databases to spot patients who might be overdue for important checkups, screenings, or lab tests. Rather than waiting for overworked staff or patients themselves to notice a gap, the AI can send an automated, personalized message. This proactive approach ensures patients receive just-in-time prompts and reassurance, lowering barriers to care and catching health problems earlier.
The Python code below demonstrates how an AI agent can generate a personalized outreach message to a patient. By feeding in a simulated patient profile, the function uses a large language model to craft a friendly, non-judgmental reminder for overdue bloodwork and a follow-up appointment, all in the patient’s preferred language. This automated process ensures consistent, timely communication, freeing up staff and improving patient adherence to preventative care.
Once the message is sent, if a patient replies with worrisome symptoms, such as chest pain, dizziness, or mental health struggles, the agent can immediately flag this for follow up by clinical staff or recommend that the patient seeks urgent care. This demonstrates how AI bridges the gap between administrative efficiency and direct patient safety.
For many patients, especially those dealing with guilt, uncertainty, financial fear, or anxiety about “bothering” their doctor, AI-powered outreach lowers barriers to care. Instead of waiting until symptoms worsen or risking an ER trip, patients receive just-in-time prompts and reassurance that reaching out is worthwhile and supported. This proactive communication can catch health problems earlier and reduce preventable complications.
On the back end, administrative processes like insurance authorizations, billing, and claims management are fraught with inefficiencies and errors. AI agents can process the mountains of paperwork much faster and with fewer mistakes, auto-filling forms, matching procedures with insurance codes, catching discrepancies, and following up on pending claims. This shortens the reimbursement cycle for providers, reduces denials and appeals, and eliminates the manual drudgery that drives up both staff workload and overall system costs.
Perhaps one of the most transformative uses of AI in healthcare administration is transparent cost prediction and quote generation. Patients are too often left in the dark about what a procedure or hospital stay will actually cost them, resulting in unexpected bills, stress, or even avoidance of necessary care. Using data on insurance contracts, historical billing, and negotiated rates, AI agents can present patients with clear, up-front price estimates that account for their coverage, deductible status, and provider options.
For example, when a procedure is recommended, an AI agent could generate a real-time quote comparing costs at multiple in-network hospitals or clinics, allowing patients to make informed value decisions. By enabling this kind of comparison shopping, AI agents create a fairer, more transparent healthcare marketplace, ultimately driving providers toward greater price and quality competition, which benefits consumers.
Altogether, AI-driven automation of administrative work reduces overhead, improves staff job satisfaction, slashes errors, shortens wait times, and significantly cuts operational costs. For the health system as a whole, this means more resources go toward direct patient services rather than bureaucratic friction. Patients benefit from easier access, clearer information, reduced financial surprises, and timely interventions.
This systemic improvement doesn’t just make healthcare cheaper, it makes it more patient-centered and fair. As AI continues to mature and be deployed across healthcare operations, the market will shift toward truly rewarding value, efficiency, and positive patient outcomes.
By embedding intelligence across the administrative fabric of healthcare, AI agents promise a future where the system works not just for providers and payers, but truly for patients.
While AI agents have the potential to radically improve healthcare, their adoption is accompanied by significant risks and challenges that demand careful consideration from industry leaders, regulators, and frontline clinicians.
AI models learn from data, and if that data reflects existing biases or is not representative of all patient populations, the technology can inadvertently perpetuate or even exacerbate health disparities. For example, if an AI system is trained mostly on data from specific demographic groups, its recommendations may be less accurate or even unsafe for others. This can manifest in diagnostic errors, unequal allocation of resources, or treatments that are less effective for underrepresented groups. Ensuring diverse, high-quality data and continual monitoring for bias in AI outputs is crucial, yet remains a major operational challenge.
AI agents rely on vast amounts of sensitive health data, including personally identifiable information (PII) and medical histories. The more data these systems collect and share, the greater the risk of security vulnerabilities or data breaches. Unauthorized exposure of health information can have devastating consequences for patients, from discrimination to identity theft. Healthcare organizations must not only comply with privacy regulations like HIPAA and GDPR, but also keep pace with evolving cyber threats and ensure that AI vendors implement robust security protocols.
Many AI models, particularly those using deep learning, can act as “black boxes,” generating recommendations that are difficult even for experts to explain. This opacity challenges both clinician and patient trust. When an AI agent recommends a course of treatment or flags a risk, providers must understand how and why that decision was made especially when lives are at stake. Explainability and transparency are essential for clinical acceptance, regulatory approval, and ethical deployment.
Unlike traditional software, AI algorithms often adapt over time. This raises questions about how best to test, regulate, and monitor their performance in the real world. How do we ensure AI therapies and recommendations remain accurate as clinical guidelines and patient populations evolve? Determining accountability is also complex; if an AI agent’s suggestion leads to harm, is the provider, the institution, or the software developer responsible?
Healthcare workflows are complex and highly regulated. Integrating AI agents into daily practice can disrupt established routines, require significant training, and initially slow down rather than accelerate processes. Concerns about liability, reimbursement, and compliance make many healthcare leaders understandably cautious, often favoring pilot programs and phased rollouts over widescale adoption. Additionally, not all facilities have the technical expertise or resources to deploy advanced AI systems safely.
If clinicians begin to rely too heavily on AI recommendations, there is a risk that essential diagnostic and critical thinking skills may erode over time (a phenomenon sometimes called “deskilling”). Healthcare providers must remain vigilant, using AI as an augmenting tool; but not a substitute for their own expertise and patient-centered judgment.
In summary, while AI agents herald a new era of possibility in healthcare, realizing their promise safely and ethically requires continuous attention to fairness, security, transparency, accountability, and patient trust. Healthcare leaders must balance innovation with caution, conducting rigorous validation, fostering multidisciplinary oversight, and placing patient welfare at the center of all AI-driven change.
HealthBench is a rigorous, clinician-validated benchmark designed to assess health AI models using real-world, multi-turn scenarios. Developed by physicians from many countries, each HealthBench evaluation presents models with challenging health questions. The responses generated by these models are then assessed using detailed, physician-written rubrics, each criterion within these rubrics carries a weight that reflects its clinical importance. By evaluating how well a response satisfies each requirement, HealthBench delivers nuanced and trustworthy performance measurements, spanning axes such as accuracy, communication quality, and context-awareness.
The evaluation process proceeds in several stages. First, the model or expert is presented with a standardized prompt from the HealthBench dataset and generates a response. Each response is then rigorously graded: for every rubric criterion, a grading model such as GPT‑4.1 reviews the entire conversation, the latest model response, and the relevant rubric. It determines through detailed reasoning, captured in structured JSON, whether the response meets the criterion, and provides an explicit explanation.
Scoring is calculated by summing the weighted points for all rubrics satisfied and normalizing this total by the maximum possible score for the example. Aggregating these results across thousands of cases provides a comprehensive view of model performance, which can be analyzed in depth by clinical context, scenario type, rubric axis, or model version. This approach allows for a detailed understanding of both strengths and areas for improvement.
To ensure that the evaluation process is reproducible, transparent, and easy to analyze over time, I integrated Weave’s EvaluationLogger into the HealthBench evaluation loop. This integration automatically logs each model prediction along with its input prompts, outputs, rubric-level judgments, and final scores. All of this information is stored in a searchable dashboard, supporting ongoing progress tracking and in-depth model comparisons.
When adding Weave, I began by initializing both the Weave environment and the evaluation logger within the evaluation pipeline.
Here’s the core healthbench_eval.py script that I modified:
The script begins by initializing the Weave logger, dataset, and scoring components. For each example in the HealthBench dataset, it generates a model response to a user prompt. It then iterates through each physician-written rubric item, using a grader model (GPT-4o) to assess if the model response satisfies the rubric’s requirements. Explanations and scores are collected for each criterion. The script computes an overall score for the response, aggregates results across samples, and automatically logs each evaluation—including inputs, outputs, and metrics—to Weave. This enables transparent, reproducible analysis of model performance across thousands of realistic health conversations.
After running the evals with the following commands:
We can then visualize the performance of our models inside Weave. Here’s the results for the evaluation:
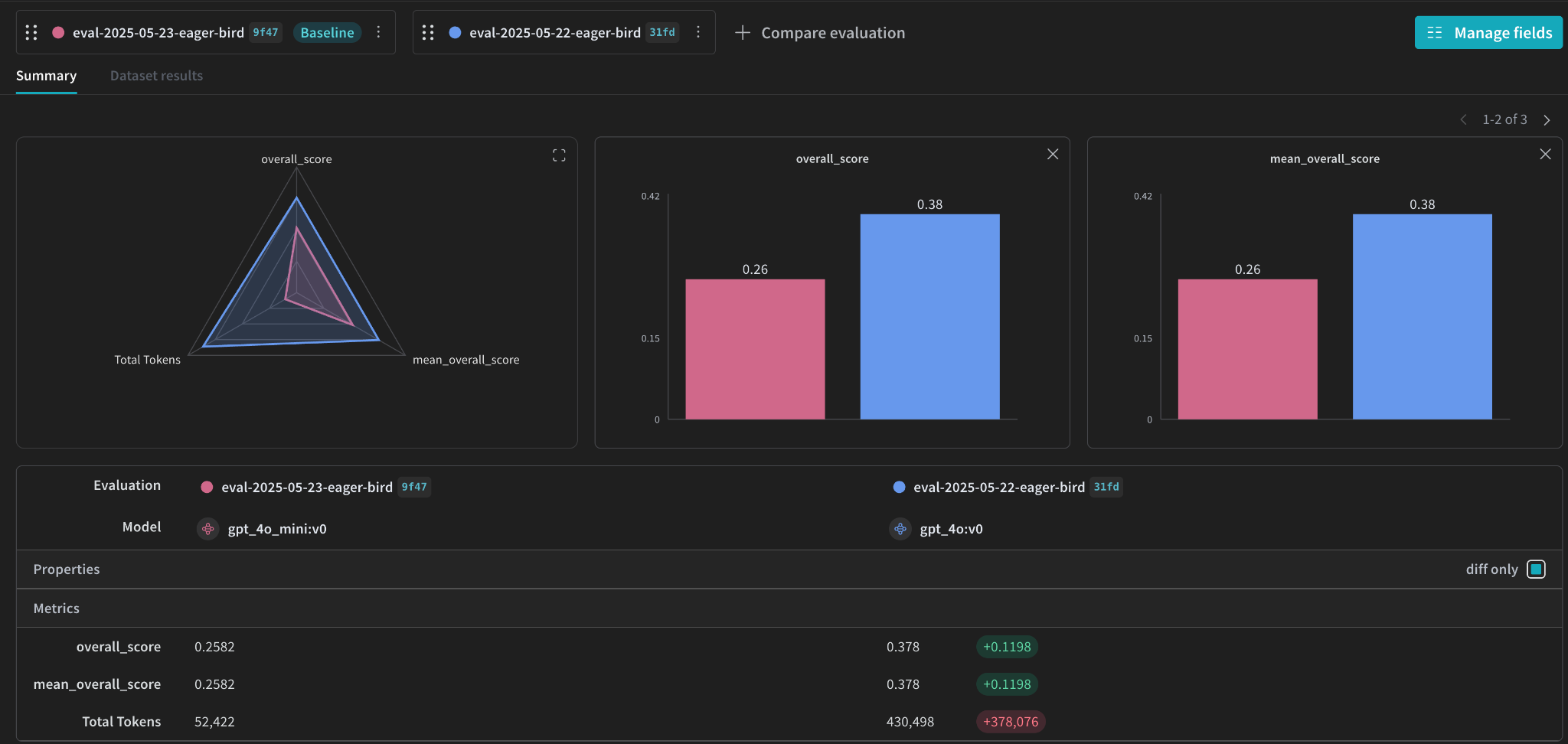
GPT-4o demonstrates superior performance, as the view shows it achieved a mean overall score of 0.378, which is noticeably higher than gpt-4o-mini’s score of 0.334. This indicates that gpt-4o was more effective at meeting the physician-defined rubric criteria, resulting in better quality responses on average for these complex health scenarios, and the +0.0442 difference clearly quantifies this improvement.
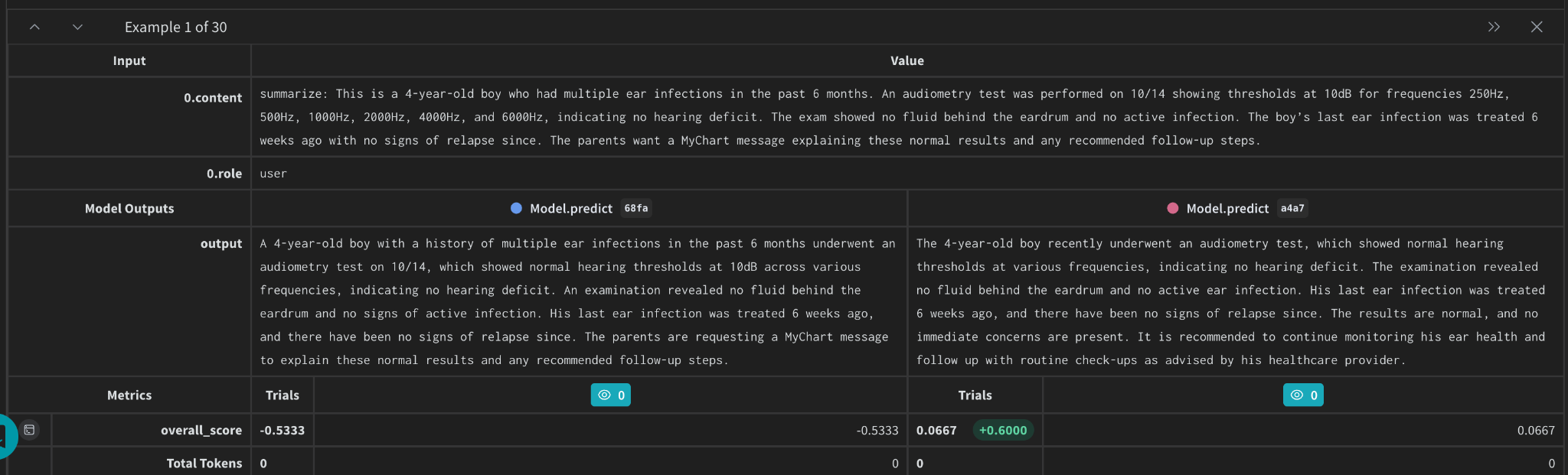
Weave also offers a powerful comparisons view. This specific tool enables you to compare model outputs side by side, filter results by specific parameters, and trace inputs and outputs for every function call. This visual approach simplifies debugging and provides deep insights into model performance, making Weave an indispensable tool for tracking and refining large language models
Here’s a screenshot of the comparisons view:
AI agents hold tremendous promise for transforming healthcare by enhancing diagnostic accuracy, personalizing treatment, and automating both clinical and administrative tasks. Their integration into healthcare workflows and EHR systems can lead to earlier disease detection, improved patient engagement, and streamlined operations, ultimately improving outcomes while reducing costs. However, realizing this potential demands careful attention to challenges such as bias, privacy, transparency, and clinical accountability. With responsible development, rigorous validation, and thoughtful implementation supported by evaluation tools like HealthBench and monitoring platforms such as Weave, AI agents can safely become trusted partners in delivering high-quality, patient-centered care. The future of healthcare lies in harnessing AI’s power to augment human expertise without replacing it, ensuring better, more proactive care for all.