

For AI teams racing to innovate, data remains the critical bottleneck. Despite the proliferation of models and frameworks, organizations across industries struggle with a fundamental challenge: accessing high-quality data to train and improve their AI systems. Healthcare providers sit on valuable patient data they can’t use due to privacy regulations. Financial institutions navigate complex compliance requirements just to begin AI development. And many teams face use cases where relevant datasets simply don’t exist.
That’s where Gretel is changing the landscape for AI development. The leading synthetic data platform allows users to generate high-quality synthetic datasets with the same characteristics as real data, allowing AI teams to improve their models without having to compromise on privacy, or moving slowly due to being hampered by bottlenecks.
“I think that’s my single favorite feature of synthetic data, and the most powerful part of it, is this incredibly fast data flywheel you can build,” said co-founder and CPO Alex Watson. “What we’re enabling is fast data experimentation, similarly to how Weights & Biases allowed us to 10x our own experimentation efforts.”
Designing synthetic data with Gretel Navigator
At the heart of Gretel’s platform is Navigator, a purpose-built compound AI system that transforms data generation from a bottleneck into a competitive advantage. Navigator combines large language models with specialized agents to handle everything from initial data design to comprehensive validation and evaluation.
“It starts with what we call designing data, where you need to know what your task is, and then you can design data for that task,” explains Watson. For example, a healthcare provider might use Navigator to generate synthetic patient records that maintain statistical patterns while eliminating privacy concerns. Or a financial institution could create synthetic transaction data to train fraud detection models.
The system’s power lies in its flexibility and speed. “You don’t have to wait to go back and collect more data, or curate massive web-crawled systems, or pay humans to label data,” Watson notes. “You can just adjust your prompts, generate more data where you had gaps in your evaluations, and iterate quickly.”
One of Gretel’s customers developing a commercial large language model (LLM) faced challenges in meeting their high standards for SQL performance. To overcome this, they leveraged Gretel’s synthetic data to generate high-quality SQL datasets. After integrating these datasets into their training pipeline, their state-of-the-art Text-to-SQL model achieved a 62% improvement in overall performance and a 35% enhancement in SQL task-specific correctness—all within just a few weeks.
Gretel users like them discovered what many Weights & Biases users already know: the key to AI innovation lies in rapid data experimentation. While ML teams traditionally focused on tweaking model architectures and training parameters, the ability to quickly experiment with the data itself often unlocks additional breakthrough improvements. This data-first approach, enabled by synthetic data generation, dramatically accelerates AI development cycles and opens new possibilities for innovation.
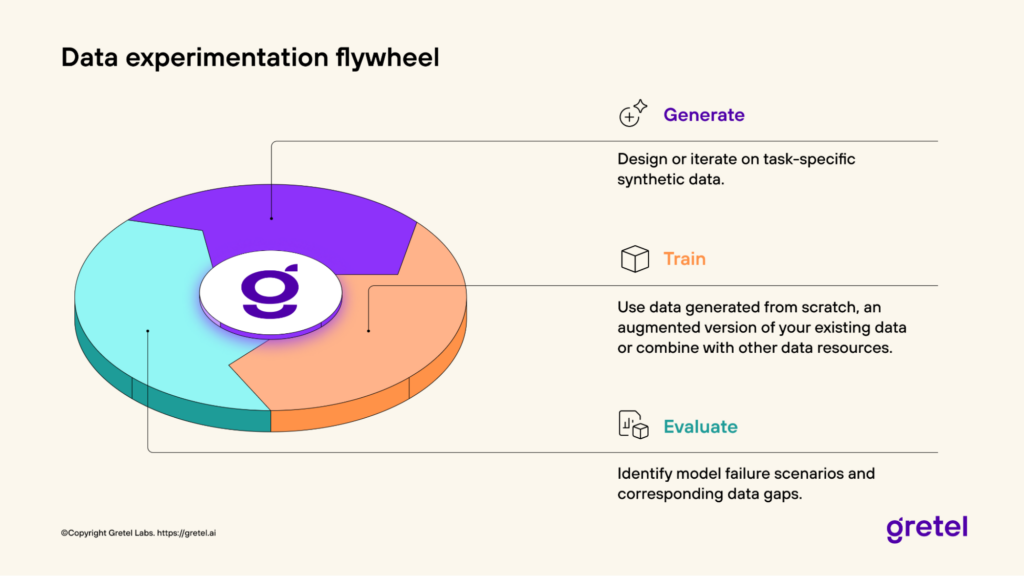
This data experimentation flywheel – generate, train, evaluate – represents a completely new paradigm for ML and AI teams. They can now design, iterate and innovate with data in a faster and more flexible manner than ever before. Teams that can experiment and iterate with data in an organized, yet innovative manner, are the ones that are much more likely to succeed in the GenAI age.
How W&B dramatically improved AI efficiency and experimentation scale at Gretel
The Gretel team first started using Weights & Biases in earnest when building the Navigator system. They wanted to fine-tune different LLMs and SLMs used by the compound AI system, on a variety of different domains – for example tabular data generation, or healthcare EHR records, or financial records. Their first approach was to crawl the web and pull back everything on that domain subject, but quickly found themselves with datasets that comprised over a trillion tokens.
“These large datasets were initially really slow to work with, hard to curate, and very expensive to fine-tune,” explained Watson. “The scale we needed to run it at was very difficult. So that’s where we started using Weights & Biases.”
Shifting to synthetic data, combined with W&B’s experiment tracking capabilities, revolutionized their development process. They were able to use synthetic datasets to help decrease their training data from a trillion to a billion tokens—a 1000x reduction—while maintaining model quality. More importantly, this efficiency gain transformed their ability to experiment.
“This is where W&B became incredible for us,” says Watson. “W&B’s logging and evaluation tools let us quickly identify gaps, make adjustments, and launch new experiment batches every few days. Instead of queuing up 5-10 experiments, we could now run 50-100 experiments in each compute block.”
The impact was immediate and dramatic: “We went from running 3-5 experiments per week to completing 250 experiments in just 45 days before our first model launch,” Watson reveals. “That level of iteration would have been impossible without both the data reduction and W&B’s ability to manage and evaluate experiments at scale.”
From Data Flywheel to AI Innovation Engine
Having experienced the power of rapid experimentation firsthand, Watson and the Gretel team are now focused on helping other organizations achieve similar transformations. But their vision extends beyond just faster development cycles.
“I’d love to see AI teams thinking of their applications themselves as flywheels,” Watson explains. “Imagine applications that don’t just serve users but learn from them—taking feedback, incorporating it into training data, and continuously improving. That’s the key to building truly successful AI applications in today’s landscape.”
By combining synthetic data generation with robust MLOps practices, Gretel is making this vision accessible to organizations across industries. The result is not just faster development, but a fundamental shift in how teams approach AI innovation.
Ready to build your own custom synthetic datasets? Get started with Gretel Navigator today, and see how easy it is to build your own data experimentation flywheel.