
Evaluating LLMs in production: From drift detection to continuous monitoring
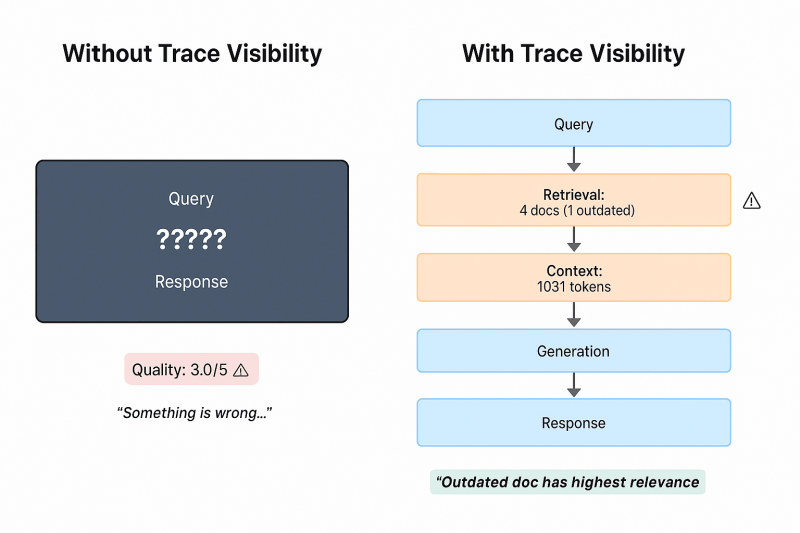
On this page The silent threat How do you build evaluation sets that stay relevant? Can automated LLM judges replace human evaluation? Example 1: Drift and cascadingfailures Example 2: Implement continuous monitoring What production metrics matter How do you integrate evaluation into your development workflow? Reproducibility and resources Closing The rise of large language models […]
Agentic AI self-correction: How to build systems that fix their own mistakes
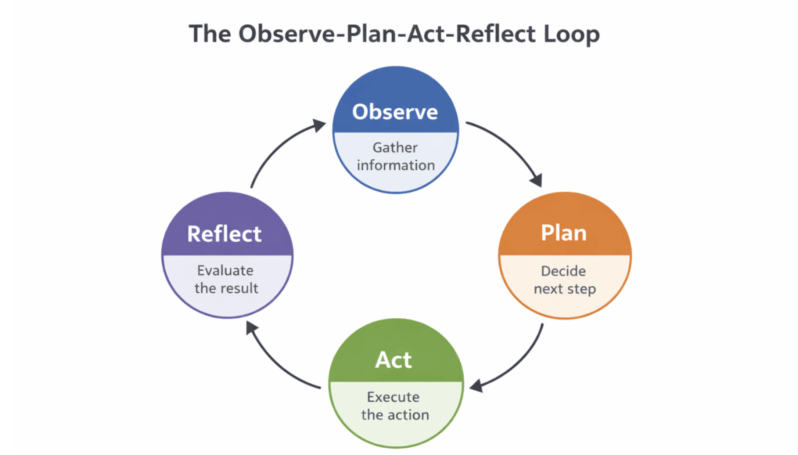
On this page Why AI must learn to self-correct The principles of agentic reasoning Architecting a self-correcting system Autonomous reflection loops Overcoming common failures MCP and advanced governance Summing things up The dream of AI has always been autonomy. But true autonomy isn’t just about finishing a task; it’s about recognizing when you’ve taken a […]
Evaluating autonomous AI agents for performance, oversight, and business value

On this page Understanding autonomous agent frameworks Core agent evaluation dimensions Progressive evaluation by agent autonomy level Component vs end-to-end evaluation Building test suites Common failure patterns Production monitoring Autonomous agent evaluation tools ROI and risk assessment Implementation roadmap The future of autonomous agent evaluation AI agents are rapidly moving into real-world use. A 2024 […]