
When quant strategies move from micro-scale latency games to modeling market structure over seconds and minutes, the entire research pipeline gets heavier. You stop dealing with a few hand-crafted signals and start working with massive datasets, event-driven simulations, replay engines, and AI models that need to be trained, fine-tuned, and stress-tested across hundreds of scenarios. That requires serious GPU clusters that can spin up fast, scale to dozens or hundreds of GPUs, run distributed training jobs, and execute full market replays without bottlenecks.
CoreWeave Cloud is purpose-built for GPU-intensive AI workloads, providing GPU-dense infrastructure with bare-metal performance, fast provisioning, and high-bandwidth interconnects. For a quant team running thousands of ML experiments, reinforcement-learning agents, or event-driven simulations, this specialized infrastructure lets you iterate at a scale and pace that general-purpose cloud infrastructure struggles to support.
But enormous compute power only matters if you can keep track of what you are actually doing. Once models evolve, datasets are regenerated, simulation parameters shift, and agents behave differently across regimes, the research surface area explodes. At that point, simply plotting a few loss curves is no longer enough. You need a persistent record of what ran, with which data, under which assumptions, and how it behaved over time, across markets, and across parameter sweeps.
This is the role Weights & Biases fills. It is a system for recording the full state of an experiment, not just its outputs. Each run is logged with configuration, dataset versions, code references, metrics, artifacts, and intermediate results, all stored centrally and indexed. Instead of having experiment context scattered across log directories and machines, everything lives in one place where runs can be compared, queried, and traced back months later.
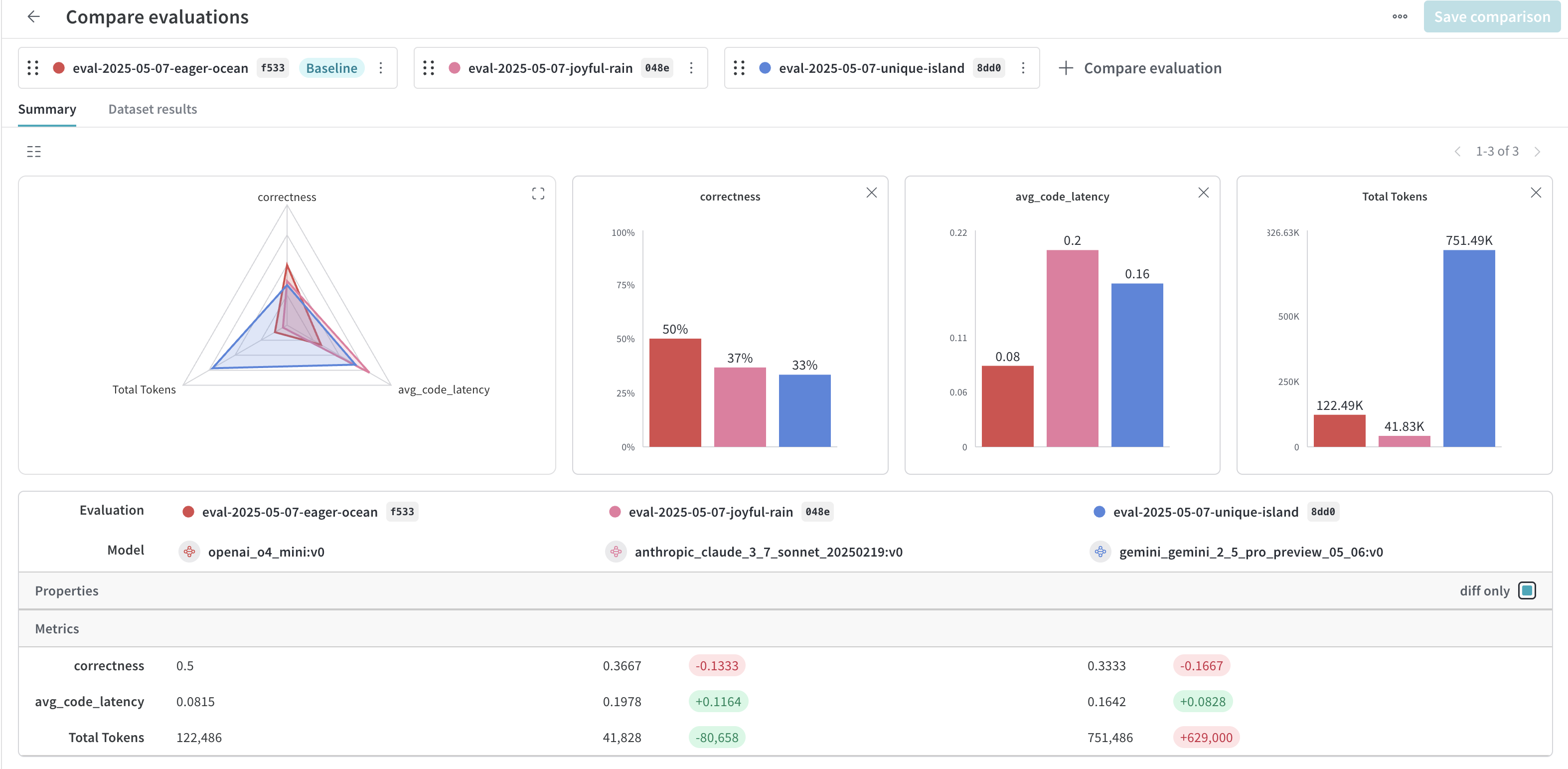
Weights & Biases is designed for the opposite regime. It assumes you are running a large number of experiments across many machines and that reproducibility is critical. Because every run is a structured object with attached metadata, it becomes possible to answer questions like why performance regressed, which data change caused it, or which hyperparameter sweep actually mattered. You can promote artifacts from research to production, audit model ancestry, and understand behavior across market regimes rather than just inspecting isolated curves.
Weights & Biases is the system that makes large-scale research possible in the first place. When experiments number in the thousands, datasets and simulators are constantly changing, and models evolve across regimes, having a complete, queryable history of what ran and why is what keeps the process sane. By treating experiments, artifacts, and metadata as first-class objects rather than loose files on disk, we turn raw compute into reliable research output and allows teams to move fast without losing track of reality.

The execution layer is evolving as AI moves beyond simple prediction into reasoning over sequences of market events. Traditionally, trading AI has focused on forecasting: estimate returns, rank assets, generate signals, then let deterministic rules convert those signals into trades. While effective in certain contexts, these systems are limited. They cannot dynamically reason about sequences of events or adapt to changing market conditions the way humans do.
Instead of following a predefined strategy, future trading agents will likely be able to explore near-unlimited strategies and discover entirely new patterns of behavior. We are entering a period where models can do more than predict. Modern AI agents can ingest diverse streams of information, maintain internal state, and reason about sequences of events. Instead of asking “what is the expected return over the next interval,” the system can evaluate questions more closely aligned with how human traders think: what just happened, what it implies, what risks it introduces, and how exposure should change as new information arrives. This does not mean intuition or gut feelings; it means explicit chains of logic applied consistently at machine scale.
Emerging LLM-powered trading agents operate within this reasoning space. They explore potential actions constrained by objectives, risk considerations, and operational limits, allowing them to adapt not just parameters but the structure of decision-making itself as conditions evolve. Equipped with general-purpose reasoning capabilities, these systems can weigh competing objectives, anticipate consequences, and update internal beliefs as new information arrives. They can integrate news, macroeconomic events, and intra-day market dynamics to adjust positions in ways that traditional predictive models cannot.
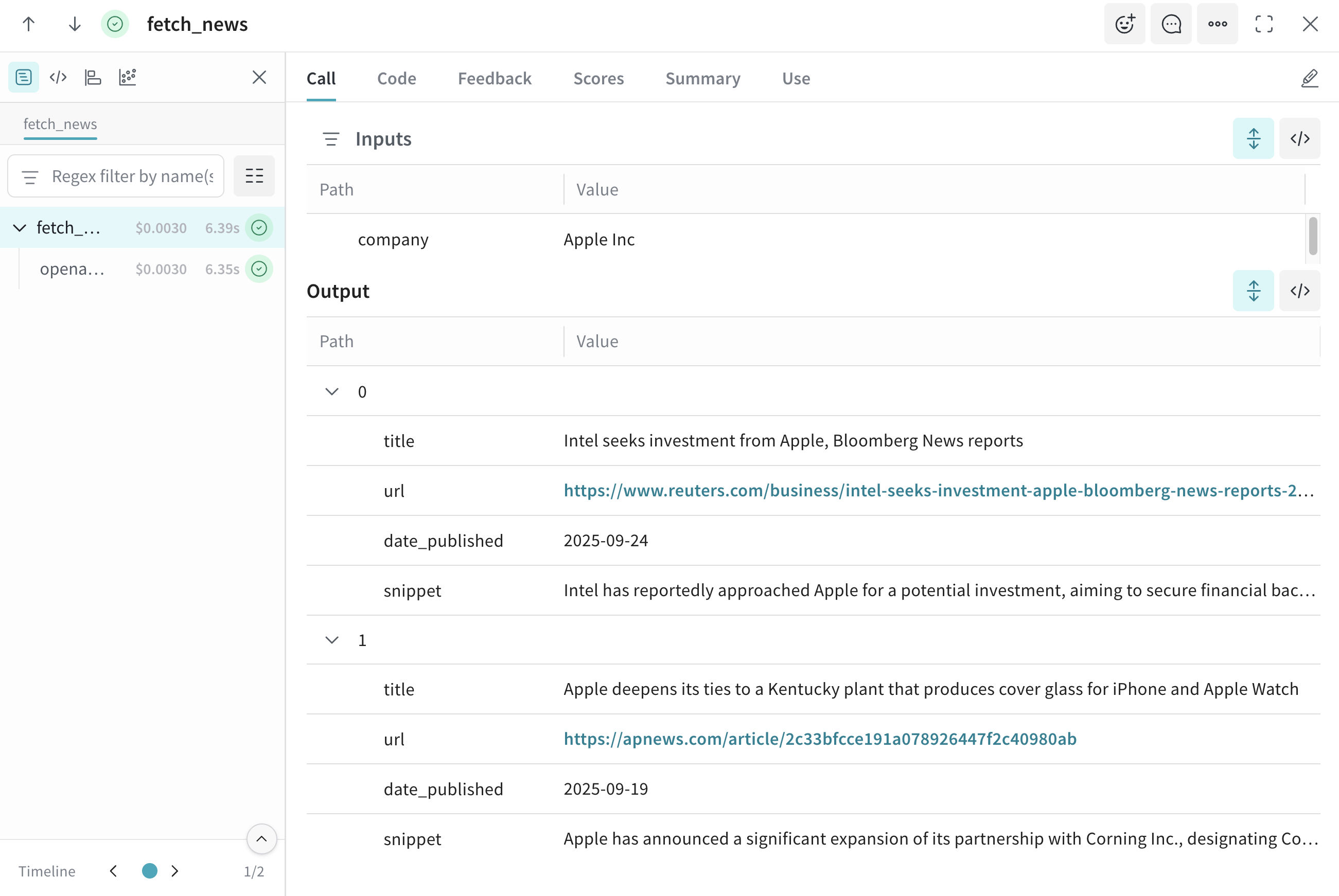
A key mechanism for learning in these agents is reinforcement learning combined with LLM reasoning. The LLM generates potential actions or trading intents based on the market state and various signals, while a simulated environment evaluates the outcomes. Agents receive a reward signal, typically combining realized PnL, risk-adjusted returns, and penalties for constraint violations, which guides the agent to reinforce profitable or low-risk behaviors. This allows strategies to emerge from economic consequences rather than purely predictive accuracy.
Training occurs primarily in simulation. Agents explore “what-if” scenarios, testing responses to volatility spikes, news events, and liquidity constraints. Conditional policies emerge naturally, for example, reducing exposure during periods of high volatility or prioritizing capital preservation when signals conflict. These behaviors arise from the interaction of reasoning and reward-guided learning, not from hard-coded rules.
As trading systems move from static signals to reasoning agents operating in real time, inference behavior becomes just as important as training scale. These agents are not making microsecond market-making decisions; they operate on seconds-to-minutes timescales where consistency matters. When a model is reacting to a breaking news headline, a macroeconomic release, or a sudden regime shift, variability in inference latency can translate directly into unpredictable behavior.
CoreWeave’s bare-metal infrastructure provides deterministic performance for this meso-scale execution regime. Eliminating noisy neighbors, virtualization overhead, and unpredictable scheduling delays ensures consistent inference timing under real-world conditions. This allows reasoning agents to behave as intended by evaluating sequences of events, updating internal state, and adjusting exposure in a controlled, repeatable manner as new information arrives.
For LLM-powered trading agents that integrate news, macro data, and intra-day signals, this consistency is especially valuable. Decisions are often coupled across time: one inference informs the context for the next. Bare-metal execution ensures that these chains of reasoning are not distorted by infrastructure-induced jitter, helping teams deploy agents whose behavior in production closely matches what they observed in simulation. In practice, this turns infrastructure into a source of reliability rather than uncertainty, supporting the transition from research agents to live trading systems without surprises.
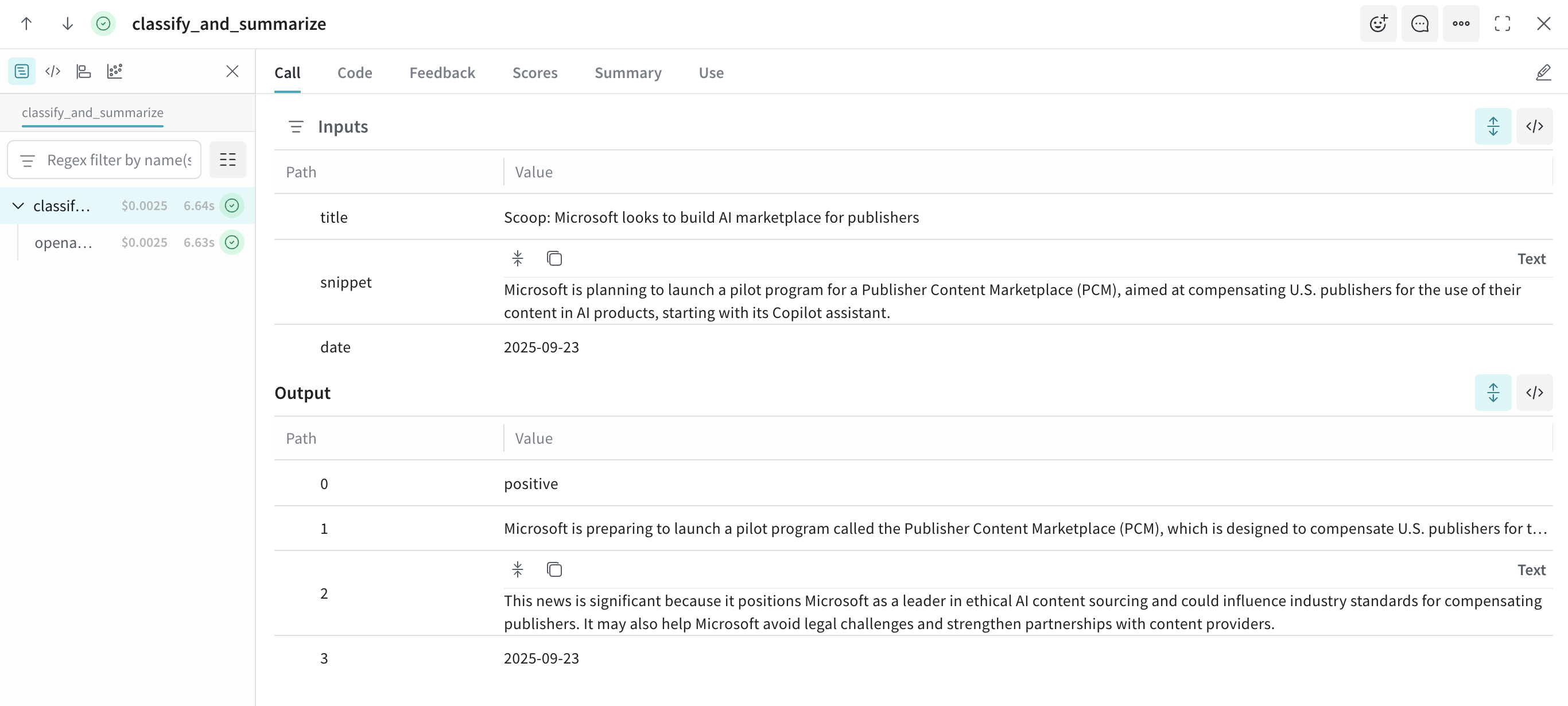
Tracing the decision process is equally important. Tools like W&B Weave allow researchers to record the full chain of LLM reasoning, capturing intermediate outputs, context embeddings, and decision rationale. This trace-level introspection is vital for understanding why an agent took a particular action, debugging unexpected behavior, and improving reproducibility across experiments. By making the reasoning process transparent, teams can refine agent policies safely, evaluate performance under varying conditions, and build confidence in the system’s behavior before deploying in the real world.
While promising, automated trading these methods remain experimental. Most work occurs in simulation or backtests, and the transition to live trading introduces additional challenges, including slippage, latency, liquidity, and regulatory compliance. Nevertheless, the combination of LLM reasoning, reinforcement learning, robust bare-metal infrastructure, and traceable decision logs represents a forward-looking framework for more adaptive and intelligent execution systems.