

LLMOps가 증가하는 이유는 무엇인가?
BERT와 GPT-2와 같은 초기 LLM은 2018년부터 있었습니다. 하지만 우리는 지금 막 – 거의 5년 후 – LLMOps라는 아이디어의 급격한 상승을 경험하고 있습니다. 주된 이유는 LLM이 2022년 12월 ChatGPT가 출시되면서 언론의 주목을 많이 받았기 때문입니다.
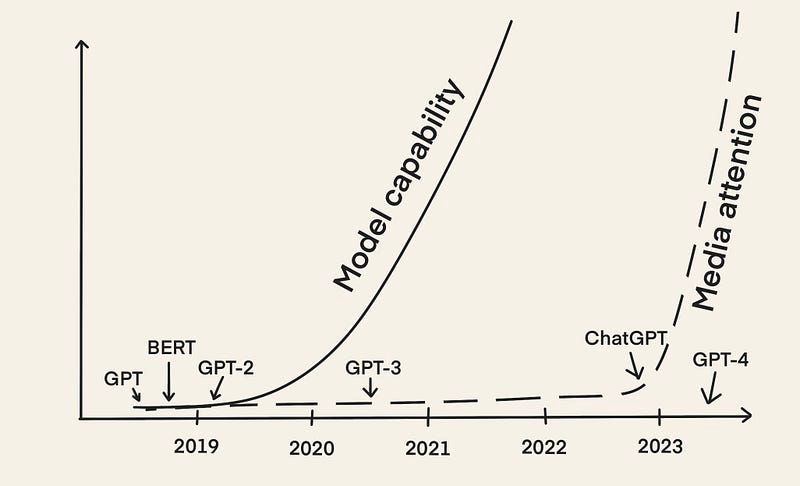
그 이후로 우리는 LLM의 힘을 활용하는 다양한 응용 프로그램을 보았습니다.예를 들어 다음과 같습니다.
많은 사람들이 LLM 기반 애플리케이션을 개발하고 프로덕션에 도입하면서 사람들은 자신의 경험을 공유하고 있습니다.
“LLM으로 멋진 것을 만드는 것은 쉽지만, 이를 사용해 프로덕션에 적합한 것을 만드는 것은 매우 어렵습니다.” – Chip Huyen [2]
프로덕션에 적합한 LLM 기반 애플리케이션을 구축하는 데는 고전적인 ML 모델로 AI 제품을 구축하는 것과는 다른 고유한 과제가 따른다는 것이 분명해졌습니다. 이러한 과제를 해결하려면 LLM 애플리케이션 라이프사이클을 관리하기 위한 새로운 도구와 모범 사례를 개발해야 합니다. 따라서 “LLMOps”라는 용어의 사용이 증가하는 것을 볼 수 있습니다.
LLMOps에는 어떤 단계가 포함됩니까?
LLMOps에 포함된 단계는 어떤 면에서 MLOps와 유사합니다. 그러나 LLM 기반 애플리케이션을 빌드하는 단계는 기초 모델의 등장으로 인해 다릅니다. LLM을 처음부터 훈련하는 대신, 사전 훈련된 LLM을 다운스트림 작업에 적응시키는 데 중점을 둡니다.
이미 1년 전, Andrej Karpathy[3]는 AI 제품 구축 프로세스가 미래에 어떻게 변화할 것인지 설명했습니다.
하지만 가장 중요한 추세는 […] 어떤 대상 작업에서 처음부터 신경망을 훈련하는 전체 설정이 […] 미세 조정으로 인해 빠르게 구식이 되어가고 있다는 것입니다. 특히 GPT와 같은 기초 모델의 등장으로 인해 그렇습니다. 이러한 기초 모델은 상당한 컴퓨팅 리소스를 갖춘 소수의 기관에서만 훈련되고, 대부분의 응용 프로그램은 네트워크 일부의 가벼운 미세 조정, 신속한 엔지니어링 또는 더 작고 특수한 목적의 추론 네트워크로의 데이터 또는 모델 증류의 선택적 단계를 통해 달성됩니다. […] – Andrej Karpathy [3]
이 인용문은 처음 읽을 때 압도적일 수 있습니다. 하지만 지금까지 일어난 모든 일을 정확하게 요약하고 있으므로 다음 하위 섹션에서 단계별로 풀어보겠습니다.
1단계: 기초 모델 선택
기초 모델은 광범위한 다운스트림 작업에 사용할 수 있는 방대한 양의 데이터로 사전 훈련된 LLM입니다. 기초 모델을 처음부터 훈련하는 것은 복잡하고 시간이 많이 걸리며 엄청나게 비용이 많이 들기 때문에 필요한 훈련 리소스를 보유한 기관은 극소수에 불과합니다[3].
관점을 바꾸어 설명하자면 Lambda Labs의 2020년 연구 에 따르면 , Tesla V100 클라우드 인스턴스를 사용하여 OpenAI의 GPT-3(매개 변수 1,750억 개)를 훈련하려면 355년과 460만 달러가 필요합니다.
AI는 현재 커뮤니티에서 “Linux 모멘트”라고 부르는 것을 겪고 있습니다. 현재 개발자는 성능, 비용, 사용 편의성 및 유연성 간의 균형을 기반으로 두 가지 유형의 기반 모델 중에서 선택해야 합니다. 독점 모델 또는 오픈 소스 모델입니다.
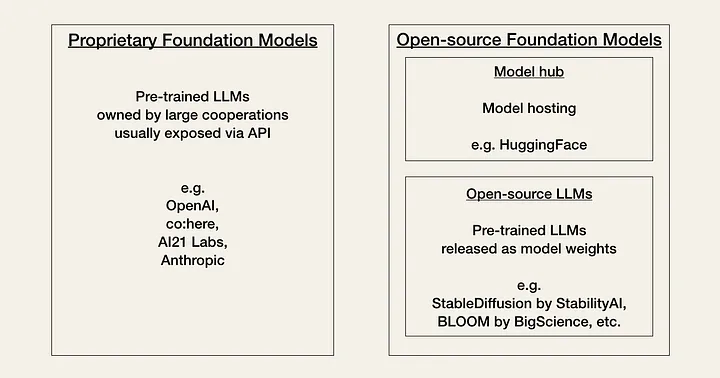
독점 모델은 대규모 전문가 팀과 대규모 AI 예산을 보유한 회사가 소유한 폐쇄형 소스 기반 모델입니다. 일반적으로 오픈소스 모델보다 크고 성능이 더 좋습니다. 또한 기성품이며 일반적으로 사용하기가 매우 쉽습니다.
독점 모델의 주요 단점은 비싼 API(애플리케이션 프로그래밍 인터페이스)입니다. 또한, 폐쇄형 소스 기반 모델은 개발자의 적응에 대한 유연성이 적거나 전혀 없습니다.
독점 모델 제공자의 예는 다음과 같습니다.
-
오픈AI (GPT-3, GPT-4)
-
AI21 랩스 (쥬라기-2)
-
인류학적 (클로드)
오픈소스 모델은 종종 HuggingFace 에서 커뮤니티 허브로 구성되고 호스팅됩니다 . 일반적으로 이들은 독점 모델보다 기능이 낮은 더 작은 모델입니다. 하지만 장점은 독점 모델보다 비용 효율적이고 개발자에게 더 많은 유연성을 제공한다는 것입니다.
오픈소스 모델의 예는 다음과 같습니다.
-
BigScience의 BLOOM
2단계: 다운스트림 작업에 대한 적응
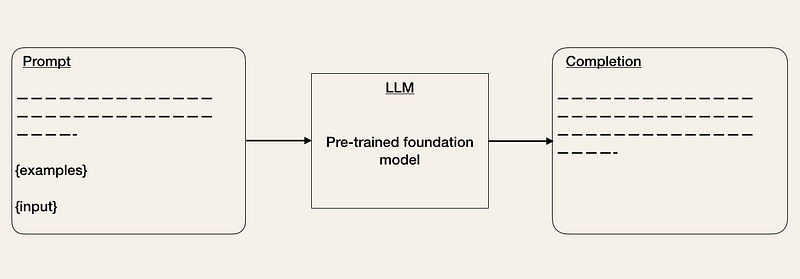
기초 모델을 선택하면 API를 통해 LLM에 액세스할 수 있습니다. 다른 API로 작업하는 데 익숙하다면 LLM API로 작업하는 것은 처음에는 약간 이상하게 느껴질 수 있습니다. 어떤 입력이 어떤 출력을 일으키는지 미리 명확하지 않기 때문입니다. 텍스트 프롬프트가 주어지면 API는 텍스트 완성을 반환하여 패턴과 일치시키려고 시도합니다.
다음은 OpenAI API를 사용하는 방법의 예 입니다 . API 입력을 프롬프트로 제공합니다. 예: prompt = “이것을 표준 영어로 수정하세요:\n\n그녀는 시장에 가지 않았습니다.”.
 API는 완료 응답 [‘choices’][0][‘text’] = “그녀는 시장에 가지 않았다.”를 포함하는 응답을 출력합니다.
API는 완료 응답 [‘choices’][0][‘text’] = “그녀는 시장에 가지 않았다.”를 포함하는 응답을 출력합니다.
가장 큰 과제는 LLM이 강력함에도 불구하고 전능하지 않다는 것입니다. 따라서 핵심 질문은 원하는 결과를 내는 LLM을 어떻게 취득할 수 있느냐는 것입니다.
생산 설문 조사 [4] 에서 응답자가 언급한 우려 사항 중 하나는 모델 정확도와 환각이었습니다. 즉, 원하는 형식으로 LLM API에서 출력을 가져오는 데 몇 번의 반복이 필요할 수 있으며, LLM은 필요한 특정 지식이 없으면 환각을 볼 수도 있습니다. 이러한 우려 사항을 해결하기 위해 다음과 같은 방법으로 기초 모델을 다운스트림 작업에 적용할 수 있습니다.
-
프롬프트 엔지니어링 [2, 3, 5]은 입력을 조정하여 출력이 기대치와 일치하도록 하는 기술입니다. 프롬프트를 개선하기 위해 다양한 요령을 사용할 수 있습니다( OpenAI Cookbook 참조 ). 한 가지 방법은 예상되는 출력 형식의 몇 가지 예를 제공하는 것입니다. 이는 제로샷 또는 퓨샷 학습 설정[5]과 유사합니다. LangChain 또는 HoneyHive 와 같은 도구 는 이미 프롬프트 템플릿을 관리하고 버전 관리하는 데 도움이 되는 도구가 등장했습니다[1].
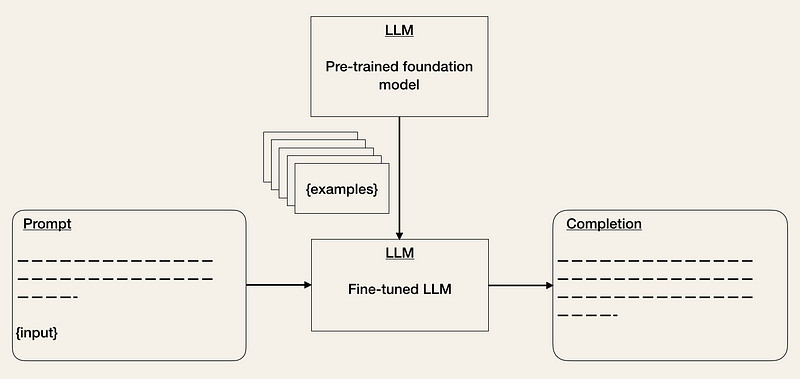
- 사전 학습된 모델의 미세 조정 [2, 3, 5]은 ML에서 알려진 기술입니다. 이 기술은 특정 작업에서 모델의 성능을 개선하는 데 도움이 될 수 있습니다. 이렇게 하면 학습 노력이 늘어나지만 추론 비용을 줄일 수 있습니다. LLM API의 비용은 입력 및 출력 시퀀스 길이에 따라 달라집니다. 따라서 입력 토큰 수를 줄이면 더 이상 프롬프트에 예를 제공할 필요가 없기 때문에 API 비용이 줄어듭니다[2].
-
외부 데이터: Foundation 모델은 종종 맥락적 정보(예: 일부 특정 문서 또는 이메일에 대한 액세스)가 부족하고 빠르게 오래될 수 있습니다(예: GPT-4는 2021년 9월 이전의 데이터로 훈련됨 ). LLM은 충분한 정보가 없으면 환각을 볼 수 있으므로 관련 외부 데이터에 대한 액세스 권한을 제공해야 합니다. LlamaIndex(GPT Index) , LangChain 또는 DUST 와 같은 도구가 이미 있으며, 이를 사용하여 LLM을 다른 에이전트 및 외부 데이터에 연결(“체인”)하는 중앙 인터페이스 역할을 할 수 있습니다[1].
3단계: 평가
클래식 MLOps에서 ML 모델은 모델의 성능을 나타내는 메트릭이 있는 보류형 검증 세트[5]에서 검증됩니다. 하지만 LLM의 성능은 어떻게 평가합니까? 응답이 좋거나 나쁜지 어떻게 결정합니까? 현재 조직에서는 모델을 A/B 테스트하는 것 같습니다[5].
LLM을 평가하는 데 도움이 되는 HoneyHive나 HumanLoop과 같은 도구가 등장했습니다.
????
4단계: 배포 및 모니터링
LLM의 완료는 릴리스 간에 크게 바뀔 수 있습니다[2]. 예를 들어, OpenAI는 부적절한 콘텐츠 생성(예: 증오 표현)을 완화하기 위해 모델을 업데이트했습니다. 그 결과, Twitter에서 “AI 언어 모델로서”라는 문구를 검색하면 이제 수많은 봇이 표시됩니다.
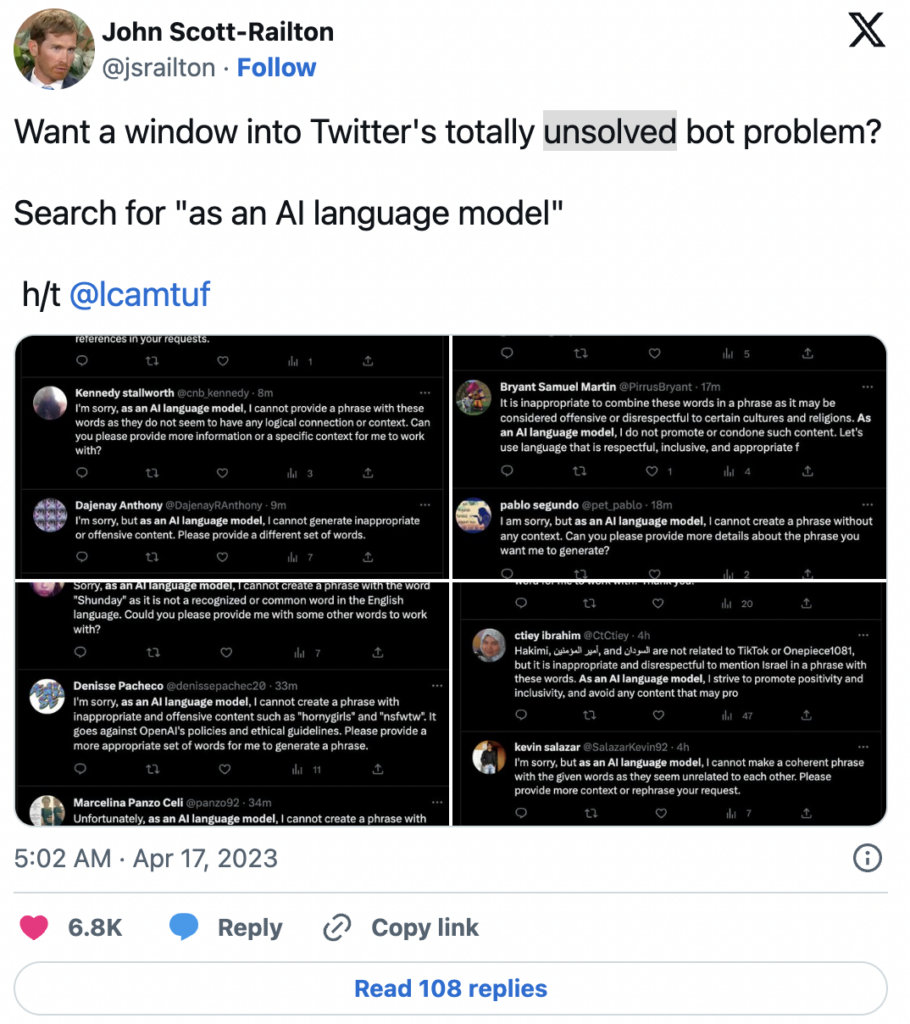 이는 LLM 기반 애플리케이션을 구축하려면 기본 API 모델의 변경 사항을 모니터링해야 함을 보여줍니다.
이는 LLM 기반 애플리케이션을 구축하려면 기본 API 모델의 변경 사항을 모니터링해야 함을 보여줍니다.