
AI agents are rapidly transforming the healthcare landscape, ushering in a new era of innovation and efficiency. These intelligent tools, capable of processing vast amounts of medical data and learning from complex patterns, are redefining how care is delivered to patients and managed by providers. By integrating AI agents into healthcare systems, hospitals and clinics can harness advanced decision-making support, enabling clinicians to make faster, more accurate diagnoses and create personalized treatment plans tailored to each patient’s unique needs.

For patients, AI agents promise a more proactive and connected healthcare experience; reminding them of important checkups, monitoring their well-being in real time, and prompting early interventions before problems escalate. Healthcare providers, on the other hand, benefit from reduced administrative burdens, enhanced data-driven insights, and greater operational efficiency across their practices. From streamlining scheduling and claims processing to flagging potential medical errors and suggesting next steps, AI agents are poised to revolutionize the delivery and management of healthcare. As the adoption of AI becomes more widespread, its intelligent integration within electronic health records and healthcare workflows holds the potential to dramatically improve outcomes, patient satisfaction, and the overall quality of care.
Methods for Automated Hyperparameter Optimization
-
Grid Search
Grid Search
Inputs
-
A set of hyperparameters you want to optimize
-
A discretized search space for each hyperparameter either as specific values
-
A performance metric to optimize
-
(Implicit number of runs: Because the search space is a fixed set of values, you don’t have to specify the number of experiments to run)

Steps
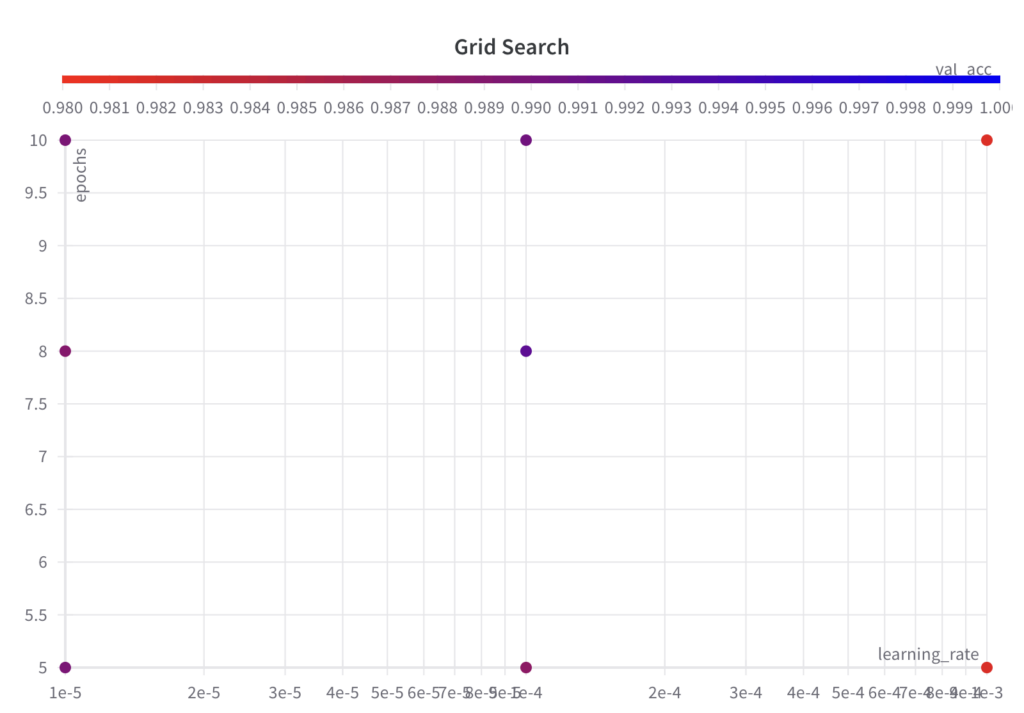
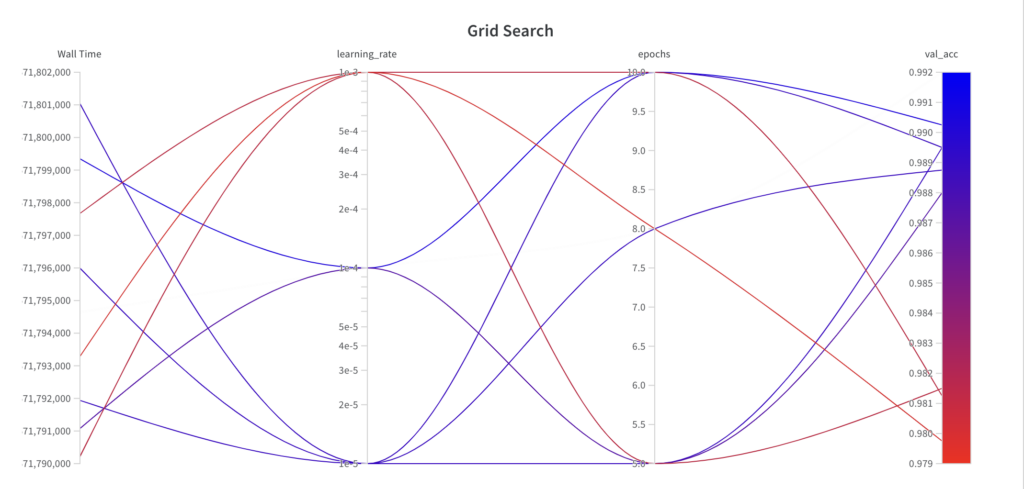
Output
-
The grid search algorithm iterates over the grid of hyperparameter sets as specified.
-
Since grid search is an uninformed search algorithm, the resulting performance doesn’t show a trend over the runs.
-
The best val_acc score is 0.9902
Advantages
-
Simple to implement
-
Can be parallelized: because the hyperparameter sets can be evaluated independently
Disadvantages
-
Not suitable for models with many hyperparameters: this is largely because the computational cost grows exponentially with the number of hyperparameters
-
Uninformed search because knowledge from previous experiments is not leveraged. You may want to run the grid search algorithm several times with a fine-tuned search space to achieve good results.
Random Search
Inputs
-
A set of hyperparameters you want to optimize
-
A continuous search space for each hyperparameter as a value range
-
A performance metric to optimize
-
Explicit number of runs: Because the search space is continuous, you must manually stop the search or define a maximum number of runs.

Steps
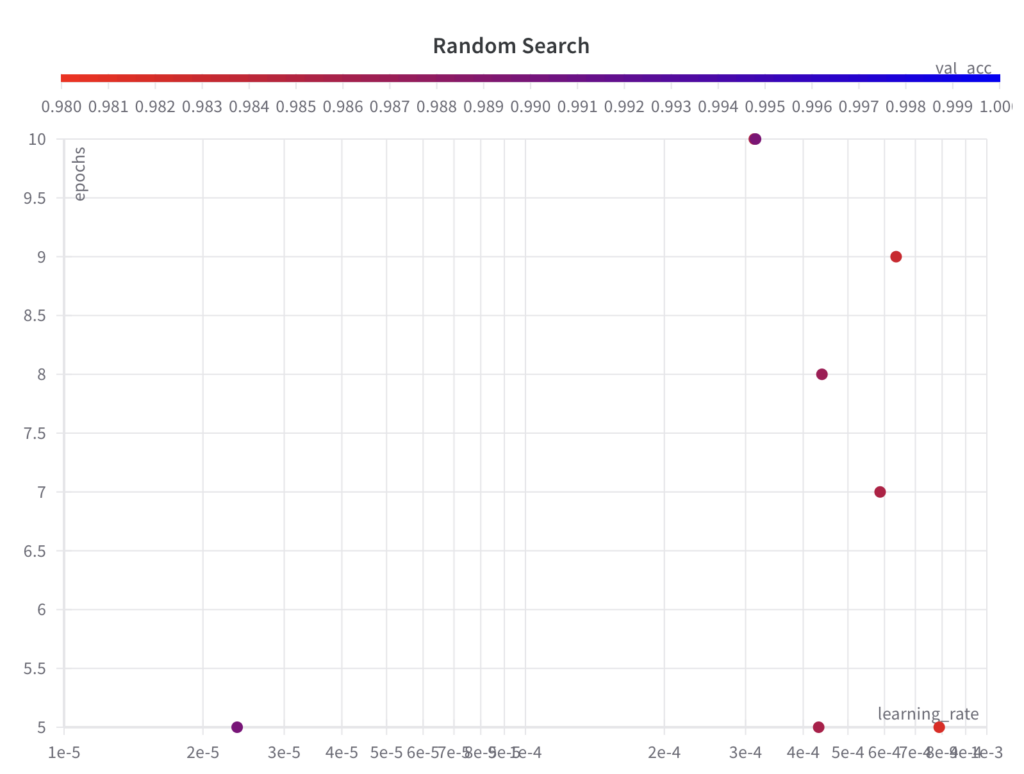
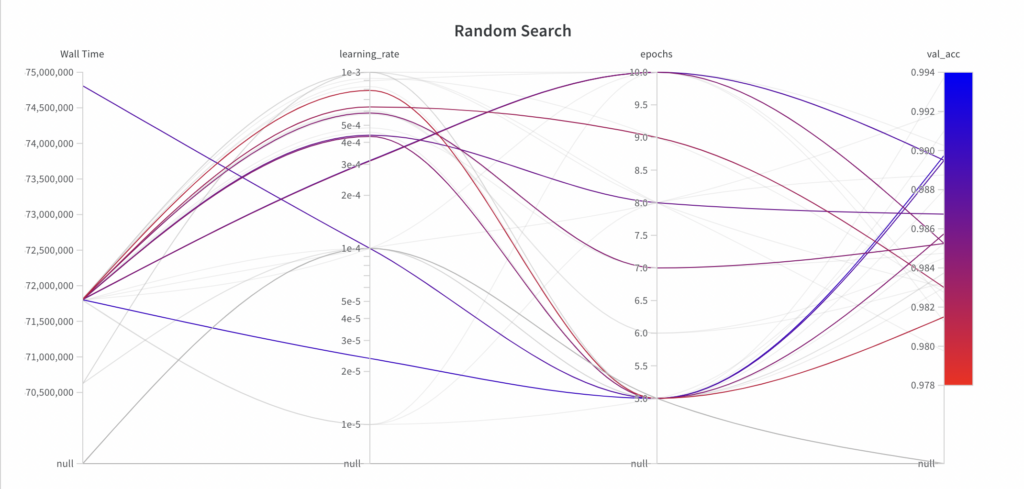
Output
-
While random search samples values from the full search space for the hyperparameter epochs, it doesn’t explore the full search space for the hyperparameter learning_rate within the first few experiments.
-
Since random search is an uninformed search algorithm, the resulting performance doesn’t show a trend over the runs.
-
The best val_acc score is 0.9868, which is worse than the best val_acc score achieved with grid search (0.9902). The main reason for this is assumed to be the fact that the learning_rate has a large impact on the model’s performance, which the algorithm failed to sample properly in this example.
Advantages
-
Simple to implement
-
Can be parallelized: because the hyperparameter sets can be evaluated independently
-
Suitable for models with many hyperparameters: Random search is guaranteed to be more effective than grid search for models with many hyperparameters and only a small number of hyperparameters that affect the model’s performance [1]
Disadvantages
-
Uninformed search because knowledge from previous experiments is not leveraged. You may want to run the random search algorithm several times with a fine-tuned search space to achieve good results.
Bayesian Optimization
Inputs
-
A set of hyperparameters you want to optimize
-
A continuous search space for each hyperparameter as a value range
-
A performance metric to optimize
-
Explicit number of runs: Because the search space is continuous, you must manually stop the search or define a maximum number of runs.

Steps
- Step 1: Build a probabilistic model of the objective function. This probabilistic model is called a surrogate function. The surrogate function comes from a Gaussian process [2] and estimates your ML model’s performance for different sets of hyperparameters.
- Step 2: The next set of hyperparameters is chosen based on what the surrogate function expects to achieve the best performance for the specified search space.
- Step 3: Run an ML experiment for the selected set of hyperparameters and their values, and evaluate and log its performance metric.
- Step 4: After the experiment, the surrogate function is updated with the last experiment’s results.
- Step 5: Repeat steps 2 – 4 for the specified number of trial runs.
Output
-
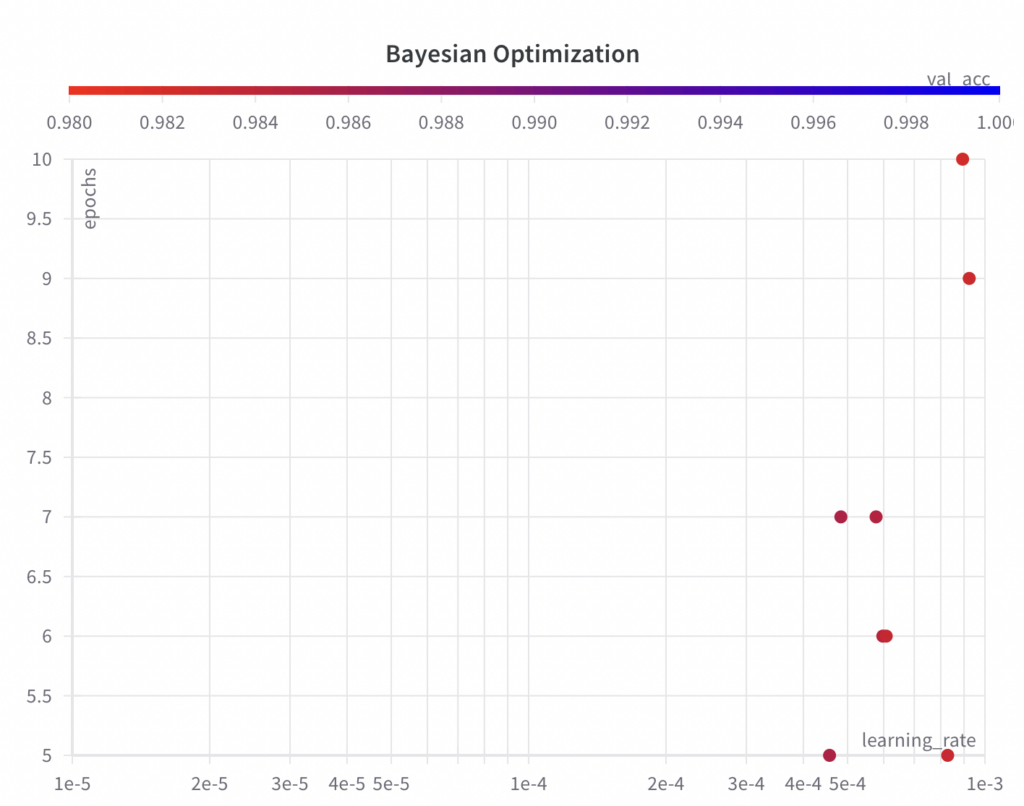
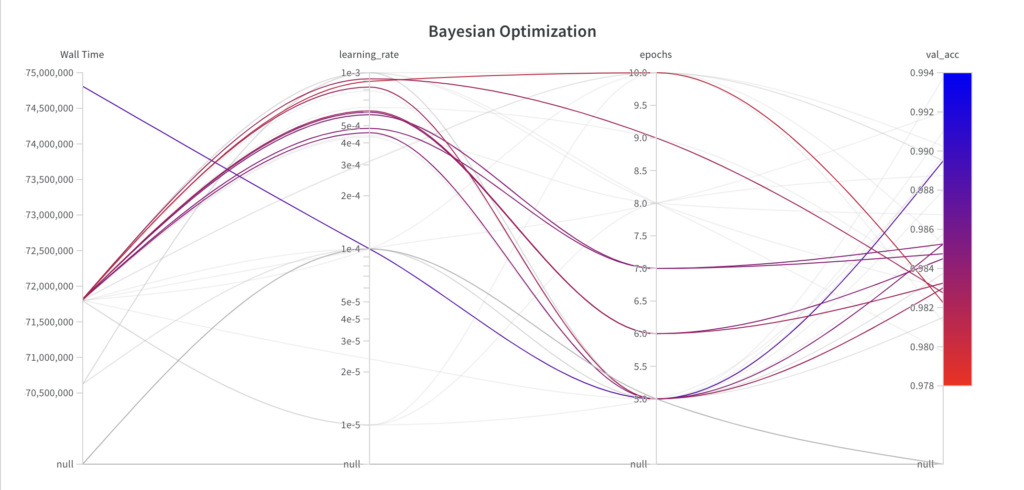
While the Bayesian optimization algorithm samples values from the full search space for the hyperparameter epochs, it doesn’t explore the full search space for the hyperparameter learning_rate within the first few experiments.
-
Since the Bayesian optimization algorithm is an informed search algorithm, the resulting performance shows improvements over the runs.
-
The best val_acc score is 0.9852, which is worse than the best val_acc score achieved with grid search (0.9902) and random search (0.9868). The main reason for this is assumed to be the fact that the learning_rate has a large impact on the model’s performance, which the algorithm failed to sample properly in this example. However, you can see that the algorithm has already begun to decrease the learning_rate to achieve better results. If given more runs, the Bayesian optimization algorithm could potentially lead to hyperparameters which result in a better performance.
Advantages
-
Suitable for models with many hyperparameters
-
Informed search: Takes advantage of knowledge from previous experiments and thus can converge faster to good hyperparameter values
Disadvantages
-
Difficult to implement
-
Can’t be parallelized because the next set of hyperparameters to be evaluated depends on the previous experiment’s results