Current best practices for training LLMs from scratch
REINFORCEMENT LEARNING THROUGH HUMAN FEEDBACK (RLHF)
RLHF RLHF (Reinforcement Learning with Human Feedback) extends instruction tuning by incorporating human feedback after the instruction tuning step to improve model alignment with user expectations.
Pre-trained LLMs often exhibit unintended behaviors, such as fabricating facts, generating biased or toxic responses, or failing to follow instructions due to the misalignment between their training objectives and user-focused objectives. RLHF addresses these issues by using human feedback to refine model outputs.
OpenAI’s InstructGPT and ChatGPT are examples of RLHF in action. InstructGPT, fine-tuned with RLHF on GPT-3, and ChatGPT, based on the GPT-3.5 series, demonstrate significant improvements in truthfulness and reductions in toxic outputs while incurring minimal performance regressions (referred to as the “alignment tax”).
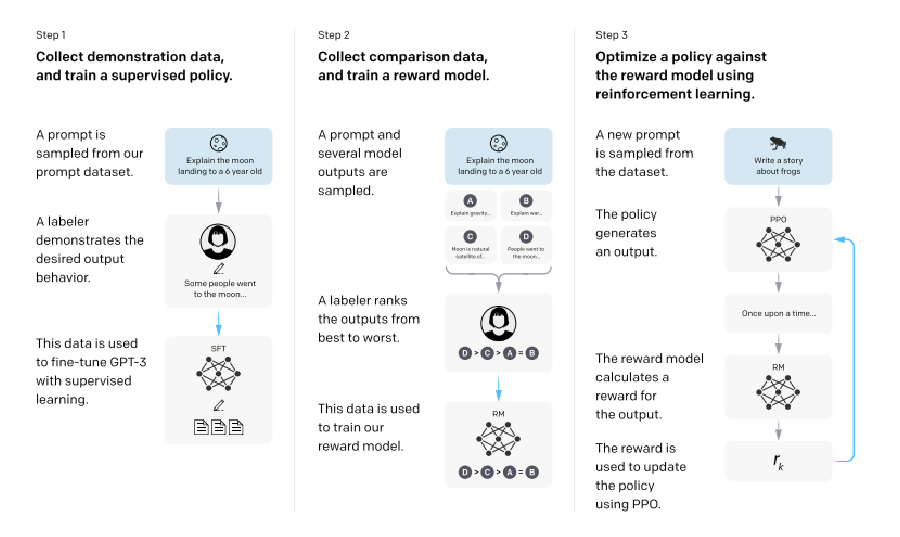
Steps in RLHF:
Instruction Tuning: Collect a dataset of labeler demonstrations showcasing desired model behavior and fine-tune the pre-trained LLM using supervised learning.
Reward Model Training: Collect a dataset of comparisons between model outputs, where labelers indicate their preferred outputs for given inputs. Train a reward model to predict human-preferred outputs.
Policy Optimization: Optimize a policy against the reward model using reinforcement learning.
Steps 2 and 3 are iterative, with new comparison data collected and used to refine the reward model and policy further.
Companies like Scale AI, Labelbox, Surge, and Label Studio offer RLHF as a service, facilitating its adoption without requiring in-house expertise. While RLHF can impose an alignment tax, research shows promising results in minimizing these costs, making it a viable approach for improving LLM performance.
A diagram illustrating the three steps of our method: (1) supervised fine-tuning (SFT), (2) reward model (RM) training, and (3) reinforcement learning via proximal policy optimization (PPO) on this reward model, Training language models to follow instructions with human feedback
To date, RLHF has shown very promising results with InstructGPT and ChatGPT, bringing improvements in truthfulness and reductions in toxic output generation while having minimal performance regressions compared to the pre-trained GPT.
Note that the RLHF procedure does come with the cost of slightly lower model performance in some downstream tasks—referred to as the alignment tax.
Companies like Scale AI, Labelbox, Surge, and Label Studio offer RLHF as a service, so you don’t have to handle this yourself if you’re interested in going down this path. Research has shown promising results using RLHF techniques to minimize the alignment cost and increase its adoption, making it absolutely worth considering.